
상태 공간 트리(State Space Tree) - 백트래킹부터 A*알고리즘까지
수능 미적분 30번 문제를 풀 때를 생각해보자. 여러 조건들을 하나씩 확인하면서, "이건 아닌 것 같은데?"라는 직감으로 가지치기를 한다. 우리는 자연스럽게 가능성을 좁혀가며 답을 찾는다.
이런 과정을 체계적으로 표현할 수 있을까? 조건들을 트리 형태로 정리하면 문제 해결 과정을 시각적으로 이해할 수 있고, 컴퓨터로도 풀 수 있다. 이를 상태 공간 트리(State Space Tree)라고 한다. 이번 글에서는 상태 공간 트리의 개념과 이를 활용하는 알고리즘을 이야기해보려 한다.
1. 상태 공간 트리란?
상태 공간 트리는 문제를 해결하는 과정에서 거쳐갈 수 있는 모든 상태를 노드로 나타낸 트리 구조다. 각 노드는 문제 해결의 한 단계를 의미하며, 간선은 한 상태에서 다른 상태로의 전이를 나타낸다.
왜 굳이 트리로 표현할까? 트리 형태로 나타내면 체계적인 탐색이 가능해지고, 불필요한 경로를 효과적으로 제거할 수 있기 때문이다.
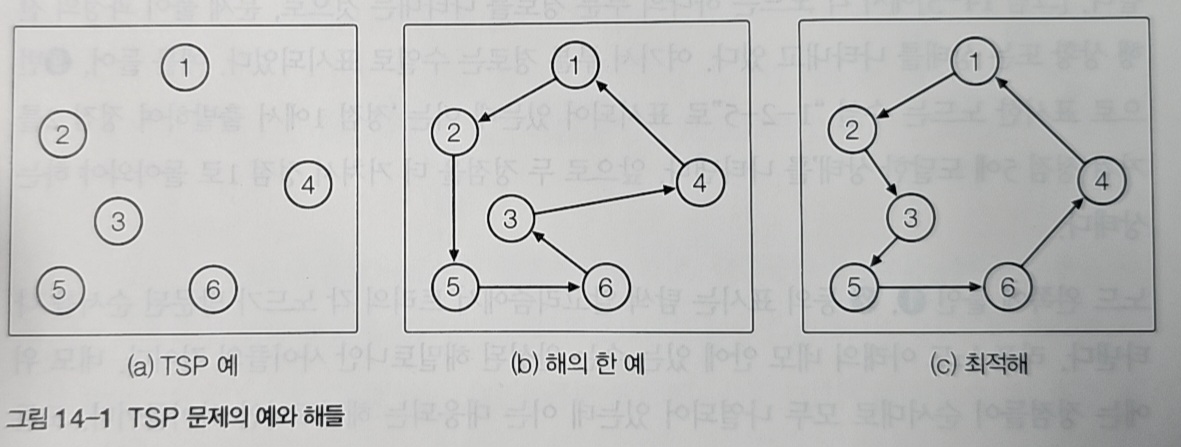
그림 14-1은 외판원 순회 문제(TSP)를 보여준다. TSP는 n개의 도시를 각각 한 번씩 방문하고 출발 도시로 돌아오는 경로 중, 총 이동 거리가 최소인 경로를 찾는 문제다.
가능한 모든 경로를 확인하면 어떨까? n개 도시의 순열은 (n-1)!/2가지이므로, 도시가 10개만 되어도 180,000가지가 넘는다. 모든 경우를 다 계산하는 것은 현실적으로 불가능하다.
다익스트라 같은 최단 경로 알고리즘도 도움이 되지 않는다. TSP는 모든 도시를 방문해야 한다는 제약이 있기 때문이다. 그렇다면 이 문제를 어떻게 효율적으로 풀 수 있을까?
핵심은 조건을 활용한 가지치기다. 탐색 중간에 "이 경로는 절대 최솟값이 될 수 없다"고 판단되면 더 이상 탐색하지 않는 것이다. 이를 위해 먼저 문제를 상태 공간 트리로 표현해보자.
1.1. 인접행렬로 표현
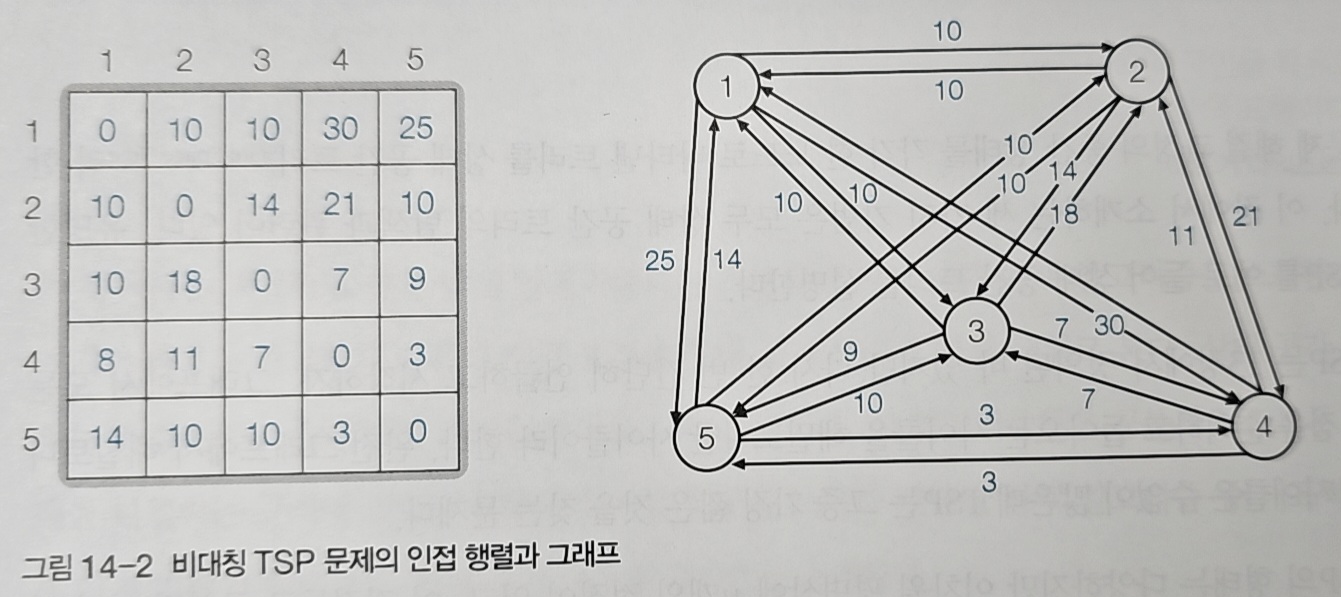
도시 간 거리를 인접행렬로 나타내면 위와 같다.
1.2. 상태 공간 트리로 표현
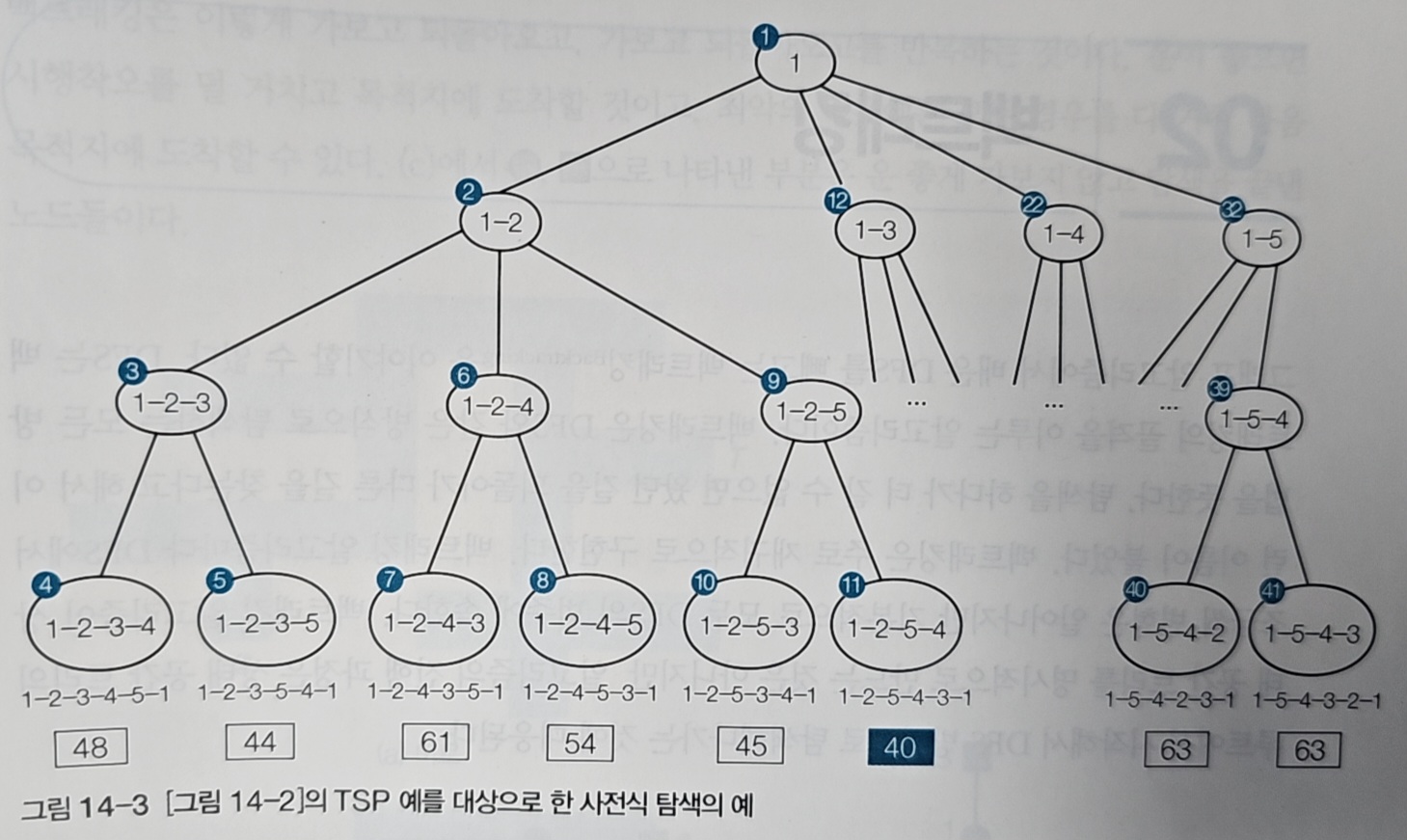
각 레벨은 방문 순서를, 각 노드는 특정 도시까지 방문한 상태를 의미한다.
위 예시는 도시가 적어서 모든 경로를 확인할 수 있었다. 하지만 도시가 10개라면? 180,000가지 경로를 일일이 계산해야 한다. 효율적으로 해결할 방법이 필요하다.
2. 백트래킹(Backtracking)
해법은 의외로 단순하다. 조건에 맞지 않으면 되돌아가면 된다.
트리를 탐색하다가 "이 경로는 최솟값이 될 수 없다"고 판단되면, 더 깊이 들어가지 않고 이전 상태로 돌아간다. 이렇게 불필요한 탐색을 건너뛰는 방법을 백트래킹(Backtracking)이라고 한다.
백트래킹은 깊이 우선 탐색(DFS)과 비슷해 보인다. 한 방향으로 끝까지 탐색하다가 막히면 되돌아간다는 점에서 같다. 차이는 가지치기(pruning)에 있다. 백트래킹은 "이 경로는 답이 될 수 없다"고 판단되면 그 즉시 되돌아간다. DFS는 끝까지 가봐야 알지만, 백트래킹은 중간에 판단해서 시간을 아낀다.
구현은 주로 재귀 함수를 사용한다. 함수 호출 스택이 자연스럽게 이전 상태로의 복귀를 처리해주기 때문이다.
2.1. 미로 찾기 문제

그림 14-4는 미로 찾기 문제와 이를 상태 공간 트리로 나타낸 예시다.
출발점 S에서 목표 지점 G까지 가는 경로를 찾는다고 하자. S → 1 → 2로 진행했는데, 2에서 더 이상 갈 곳이 없고 목표도 아니라면? 되돌아가서 1에서 3을 시도한다. 이것이 백트래킹의 동작 방식이다.
이를 의사코드로 표현하면 다음과 같다.

2.2. 색칠 문제(Graph Coloring)
백트래킹이 활용되는 또 다른 대표적인 문제를 살펴보자.

색칠 문제(Graph Coloring)는 k개의 색을 사용해 그래프의 인접한 정점들이 서로 다른 색을 갖도록 칠하는 문제다. 지도에서 인접한 지역을 다른 색으로 구분하는 상황을 떠올리면 된다.
문제를 그래프로 표현해보자. 각 구역을 정점으로, 인접한 구역을 간선으로 연결하면 된다.
n개의 정점에 k개의 색을 칠하는 경우의 수는 $k^n$가지다. 4개 정점에 3가지 색을 칠한다면? $3^4$ = 81가지다. 모든 경우를 확인하는 건 비효율적이다.
백트래킹을 사용하면 훨씬 효율적으로 해결할 수 있다. 색을 하나씩 칠하다가 "인접한 정점과 같은 색이 되었다"면 즉시 되돌아가서 다른 색을 시도하면 된다.
이를 의사코드로 표현하면 다음과 같다.


백트래킹 과정을 상태 공간 트리로 나타내면 다음과 같다.
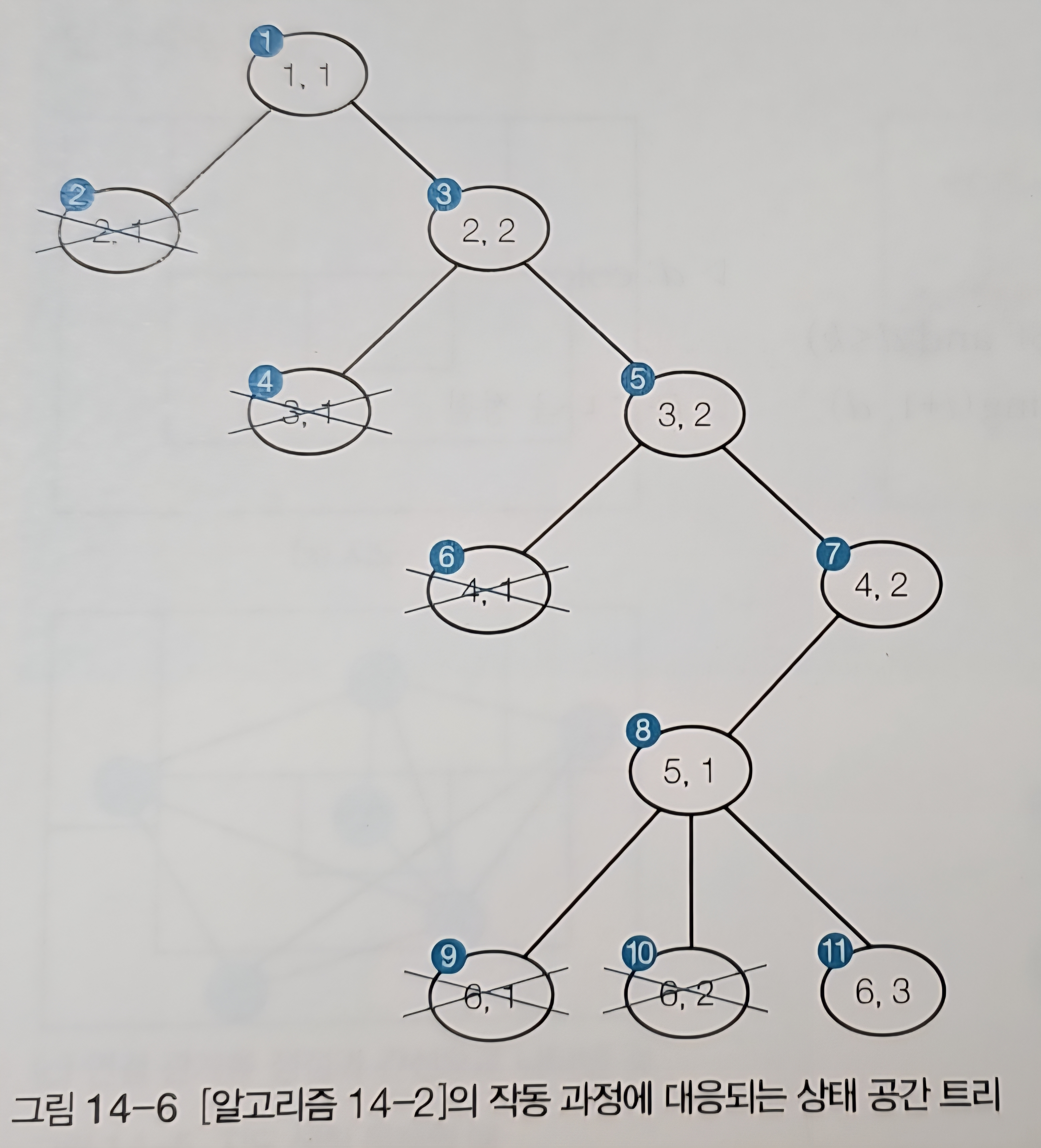
3. 한정 분기(Branch and Bound)
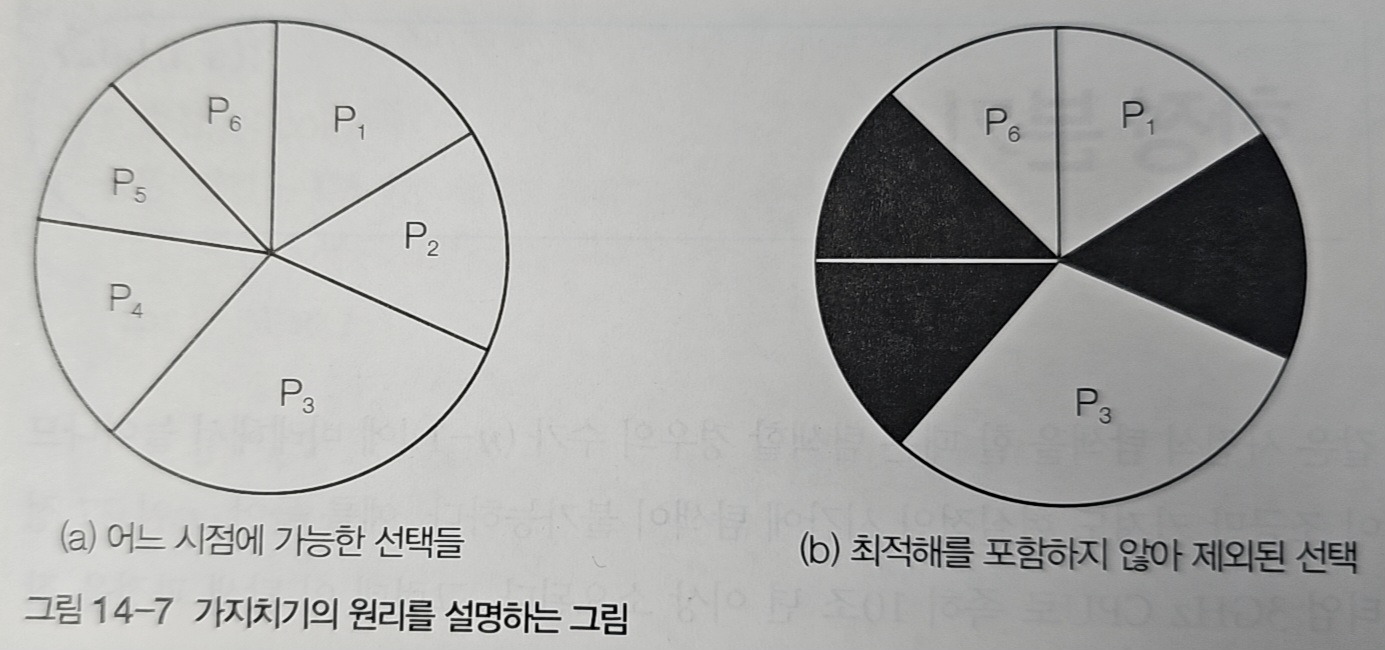
백트래킹은 가지치기를 통해 불필요한 탐색을 줄였다. 상태 공간 트리를 효율적으로 탐색하는 또 다른 방법이 있다. 바로 한정 분기(Branch and Bound)다.
한정 분기는 분기(Branch)와 한정(Bound) 두 가지 전략을 결합한 방법이다.
- 분기: 상태 공간 트리를 확장하며 탐색한다
- 한정: 최적해를 찾을 가능성이 없는 경로는 더 이상 탐색하지 않는다
핵심은 현재까지 찾은 최선의 해를 기준으로 삼는다는 것이다. "이 경로로 가면 지금까지 찾은 해보다 나을 수 없다"고 판단되면 그 즉시 가지를 잘라낸다. 백트래킹이 "조건에 맞지 않으면" 되돌아갔다면, 한정 분기는 "최적해가 될 가능성이 없으면" 되돌아간다.
3.1. 한정 분기의 동작
한정 분기를 사용하려면 두 가지 조건을 만족해야 한다.
- 상태 공간 트리로 표현 가능: 문제의 모든 해를 체계적으로 나열할 수 있어야 한다
- 한계값(Bound) 계산 가능: 현재 경로에서 도달 가능한 최선의 값을 추정할 수 있어야 한다
두 번째 조건이 특히 중요하다. "이 경로로 가면 최선의 경우에도 현재 해보다 나쁠 것"이라고 판단할 수 있어야 가지치기가 가능하기 때문이다.
3.2. TSP에 대한 한정 분기 예(상태 공간 트리)

한정 분기를 TSP에 적용한 예시를 살펴보자.
각 노드의 하한값은 다음과 같이 계산한다
(총 하한값) = 실제로 이동한 거리 + 남은 경로의 하한값
먼저 하한값 33이 어떻게 나왔는지 살펴보자.
각 도시는 TSP 경로에서 정확히 2개의 간선(들어오는 것 1개, 나가는 것 1개)에 연결된다. 각 도시에서 가장 짧은 간선 2개씩을 선택해 모두 더한 뒤 2로 나누면 이론적 최솟값을 얻을 수 있다. 이 예시에서는 그 값이 33이다.
노드 ① (시작점)
- 하한값: 0 + 33 = 33
- 아직 이동하지 않았고, 전체 문제의 이론적 최솟값은 33
노드 ② (1→2)
- 하한값: 10 + 23 = 33
- 도시 1에서 2로 이동 거리 = 10
- 남은 도시들(3, 4, 5)을 방문하는 최소 추정 = 23
- 33은 탐색 가능한 범위 → 계속 탐색
노드 ⑲ (1→4)
- 하한값: 30 + 23 = 53
- 도시 1에서 4로 이동 거리 = 30
- 남은 경로 추정 = 23
- 이 시점의 최선의 해가 40이라면, 53 ≥ 40 → 가지치기
한정 분기는 "지금까지 이동한 실제 거리"와 "남은 경로의 최소 추정치"를 합산하여 판단한다. 이 합이 현재까지 찾은 최선의 완성된 경로보다 크거나 같으면, 더 이상 탐색할 필요가 없다고 판단하고 가지를 잘라낸다.
핵심은 미리 판단한다는 것이다. 끝까지 가보지 않아도 하한값만으로 가지치기가 가능하다.
4. A* 알고리즘
한정 분기를 더욱 발전시킨 방법이 바로 A* 알고리즘 이다. A* 알고리즘은 최단 경로를 찾는 알고리즘으로, 우리가 이미 배운 다익스트라 알고리즘과 한정 분기의 아이디어를 결합한 방법이다.
다익스트라를 떠올려보자.
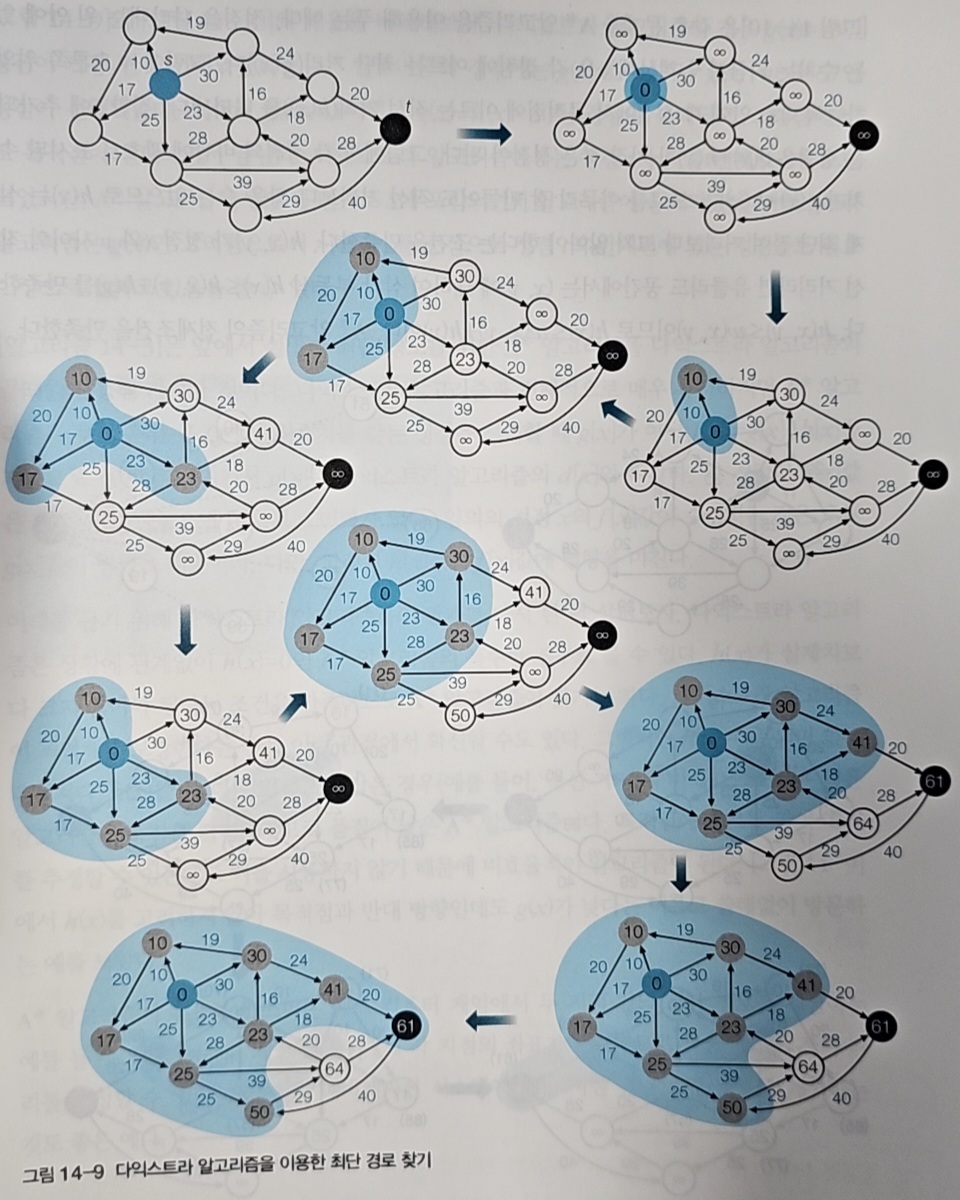
다익스트라 알고리즘은 시작점에서 각 정점까지의 최단 거리를 찾는다.
동작 방식은 간단하다. 시작점에서 각 정점까지의 거리를 계속 갱신하면서, 아직 방문하지 않은 정점 중 거리가 가장 짧은 것을 선택한다.
선택한 정점에서 인접한 정점들의 거리를 다시 갱신하고, 이를 모든 정점을 방문할 때까지 반복한다.
다익스트라의 특징은 "지금까지 온 거리"만 고려한다는 것이다. 목표가 어디에 있든 상관없이 모든 방향을 균등하게 탐색한다.
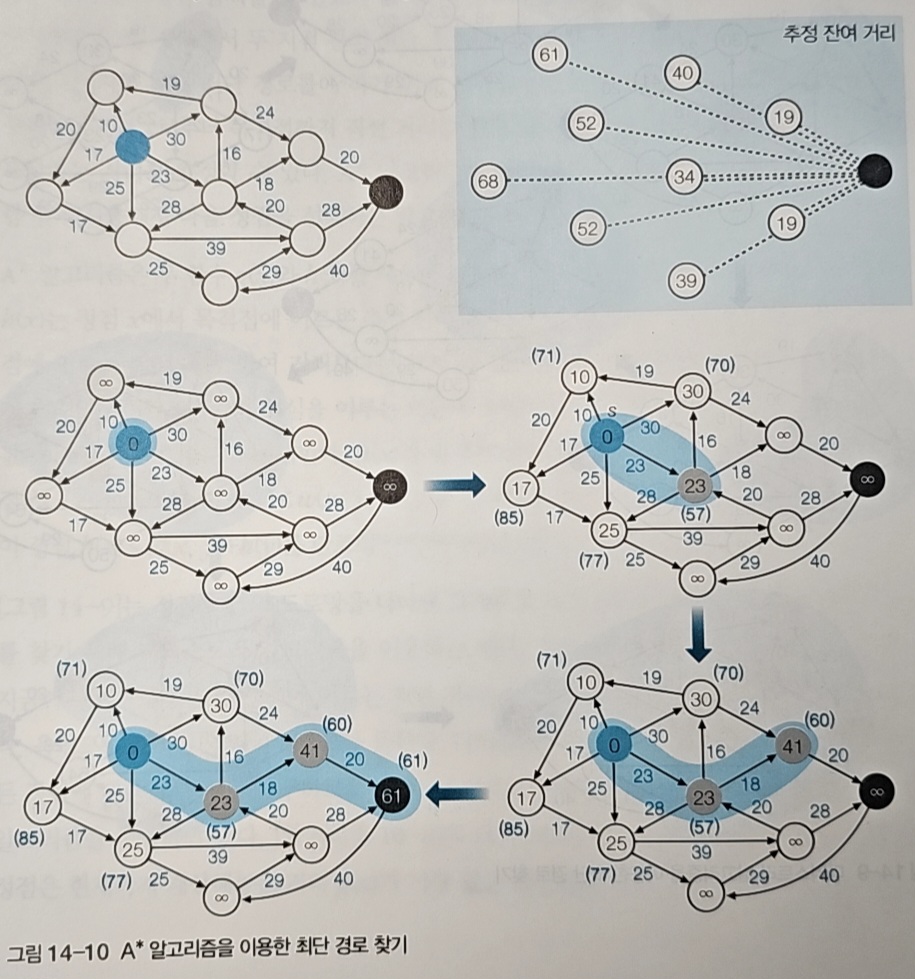
A*는 다익스트라에 한 가지 아이디어를 더한다. 바로 "목표가 저쪽에 있으니 그쪽 방향을 우선 탐색하자"는 전략이다.
A*는 다음과 같은 평가 함수를 사용한다
f(n) = g(n) + h(n)- g(n): 시작점에서 현재까지 실제로 온 거리 (다익스트라가 사용하는 값)
- h(n): 현재에서 목표까지의 예상 거리 (한정 분기의 하한값과 유사)
한정 분기에서 "실제 거리 + 남은 거리 추정"으로 하한값을 계산했던 것처럼, A*도 같은 방식으로 각 경로를 평가한다.
위 A* 그림을 예로 들어보자. 파란색 시작점에서 여러 경로를 평가하면...
- 10 + 61 = 71
- 17 + 68 = 85
- 25 + 52 = 77
- 23 + 34 = 57 ← 가장 작은 값
- 30 + 40 = 70
A*는 f(n) = 57로 가장 작은 경로(거리 23인 경로)를 선택한다. 이런 식으로 목표 방향으로 효율적으로 탐색해 나간다.
예상 거리 h(n)은 어떻게 계산할까?
예상 거리 h(n)은 보통 직선 거리를 사용한다. 이는 삼각형의 성질을 이용한 것이다. 삼각형에서 두 변의 합은 항상 나머지 한 변보다 크거나 같다. 즉, 직선 거리는 다른 어떤 우회 경로보다도 짧다.
이 성질 덕분에 h(n)은 절대 과대평가하지 않는다. 이것이 A*가 최적해를 보장하는 핵심 이유다.
대표적인 h(n) 계산 방법으로는 유클리드 거리나 맨해튼 거리 같은 것들이 있다.
A*의 의사코드는 다음과 같다.

이처럼 A*는 "지금까지 온 거리"와 "목표까지의 예상 거리"를 모두 고려하여, 최적해를 보장하면서도 효율적으로 경로를 찾는다.
출처
쉽게 배우는 알고리즘 | 문병로 | 한빛아카데미 - 예스24
귀납적 사고를 통한 문제 해결 기법 훈련이 책은 알고리즘에 대한 지식을 기반으로 제대로 된 프로그래밍을 하는 이들뿐 아니라, 알고리즘 속에 깃든 여러 가지 생각하는 방법, 자료구조, 테크
www.yes24.com
'Computer Science(컴퓨터 과학) > 알고리즘' 카테고리의 다른 글
| 하이퍼그래프(Hypergraph) - 그래프를 확장한 집합적 연결 표현 (0) | 2025.12.14 |
|---|---|
| 해시 테이블(Hash Table) (0) | 2025.12.01 |
| 문자열 매칭 알고리즘 - 원시적 방법부터 휴리스틱까지 (0) | 2025.12.01 |
| 집합의 처리를 잘 하는 Union-Find (0) | 2025.11.29 |
| 동적 프로그래밍(Dynamic Programming) (0) | 2025.11.29 |







