
집합의 처리를 잘 하는 Union-Find
친구 관계를 생각해보자.
철수는 영희와 친구고, 영희는 민수와 친구다. 그렇다면 철수와 민수는 같은 친구 그룹일까? 당연히 그렇다.
이제 친구가 100만 명이라면? 철수와 민수가 같은 그룹인지 확인하려면 모든 친구 관계를 일일이 뒤져야 할까?
Union-Find라는 자료구조는 이 문제를 빠르게 해결한다. 그룹을 합치고(Union) 찾는(Find) 작업을 효율적으로 처리한다. 이번에는 Union-Find가 어떻게 동작하는지 알아보자.
1. 집합 처리
Union-Find가 다루는 것은 집합이다.
집합이란 순서와 중복이 없는 원소들을 갖는 자료구조다.
특히 Union-Find가 다루는 집합은 특별하다. 여러 개의 집합이 존재하고, 이들은 서로 겹치지 않는다. 이를 '상호 배타적 집합'이라고 한다.
이런 집합들을 다루려면 세 가지 연산이 필요하다

컴퓨터는 이 연산들을 어떻게 구현할까?
2. 연결 리스트를 이용한 집합의 처리

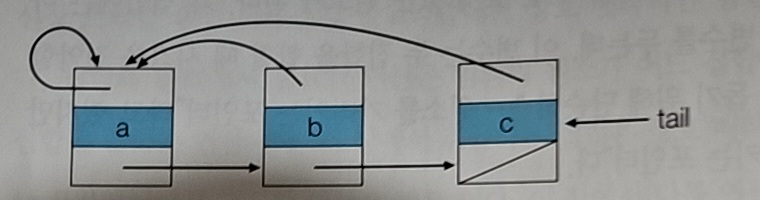
가장 먼저 생각할 수 있는 방법은 연결 리스트다.
연결 리스트는 위와 같은 구조로 되어있다. 각 노드는 다음과 같이 3개의 값을 가지고 있다.
- 원소 값
- 다음 원소를 가리키는 포인터
- 대표 원소를 가리키는 포인터
여기서 대표 원소는 연결 리스트의 맨 앞 원소이며, 위 그림에서는 a이다.
tail은 맨 뒤의 원소를 가리킨다. 이는 두 집합을 합칠 때 사용된다.
이 구조를 통해 세 가지 연산을 진행할 수 있다
Make_Set(x)
원소 x로만 이루어진 집합을 만든다.
노드 하나를 생성하고 원소를 저장한다.
대표 원소는 자기 자신을 가리키고, 다음 원소는 NIL로 설정한다.
Find_Set(x)
원소 x가 속한 집합을 찾는다.
x가 가리키는 대표 원소를 반환하면 된다.
Union(x, y)
원소 x가 속한 집합과 원소 y가 속한 집합을 하나로 합친다.

Union은 위 그림과 같이 동작한다.
한 집합의 tail을 다른 집합의 대표 원소에 연결한다.
그리고 뒤에 붙은 집합의 모든 노드들이 새로운 대표 원소를 가리키도록 변경한다.
이를 통해 연산 시간을 단축할 수 있다.
Make_Set은 하나의 원소로 집합을 초기화하는 것이므로 상수 시간이 소요된다.
Find_Set은 해당 원소의 노드에 있는 대표 원소 포인터만 반환하면 되므로 상수 시간이 소요된다.
Union은 대표 원소를 가리키는 포인터를 변경하는 데 가장 많은 시간이 소요된다. 실제 구현에서는 "큰 집합은 그대로 두고 작은 집합을 붙이기"를 통해 시간을 줄인다. 이를 "무게를 고려한 Union"이라고 한다.
무게를 고려한 Union을 사용하면, m번의 Make_Set, Union, Find_Set 중 n번이 Make_Set일 때 전체 수행 시간은 O(m+nlogn)이다.
3. 트리를 이용한 집합의 처리

연결 리스트 말고도 트리를 이용해서 Union-Find를 구현할 수 있다.
트리를 이용한 구조는 일반적인 트리와 반대다. 자식 노드가 부모 노드를 가리킨다.
임의의 노드에서 부모 포인터를 계속 따라가면 루트 노드에 도달한다.
루트 노드는 집합의 대표 노드다. 루트 노드의 부모 포인터는 자기 자신을 가리킨다.
Union은 연결 리스트보다 간단하다. 두 집합 중 한 집합의 루트가 다른 집합의 루트를 가리키도록 포인터 하나만 바꾸면 된다.

세 가지 연산을 의사코드로 나타내면 다음과 같다.

4. 연산의 효율을 향상시키기 위한 방법
트리를 이용한 방법을 더 빠르게 만들 수 있다.
방법은 두 가지다. 랭크를 이용한 Union과 경로 압축이다.
4.1. 랭크를 이용한 Union

각 노드는 자신을 루트로 하는 서브 트리의 높이 상한을 랭크(rank)에 저장한다.
Union에서 두 집합을 합칠 때, 랭크가 낮은 집합을 랭크가 높은 집합에 연결한다.
예를 들어 랭크가 2인 루트 c와 랭크가 1인 루트 e가 있다고 하자. Union을 할 때 e를 c에 연결한다. 랭크가 작은 쪽을 큰 쪽에 붙이는 것이다.
이 방법의 장점은 집합의 원소 개수를 일일이 세지 않아도 된다는 점이다. 랭크만 비교하면 되므로 빠르고 실용적이다.
이를 의사코드로 작성하면 이렇다.

아까전과 다른 점은 x'와 y'의 랭크를 찾아 비교하는 것에 있다.
4.2. 경로 압축

경로 압축은 Find_Set을 수행하면서 경로를 줄이는 방법이다. 루트를 찾아가는 과정에서 거쳐간 모든 노드가 직접 루트를 가리키도록 포인터를 변경한다.
의사코드로 작성하면 다음과 같다.

만약 x가 루트가 아니라면, x의 부모를 루트로 직접 연결한다. 이렇게 하면 다음번 Find_Set이 훨씬 빠르다.
* Union-Find의 연산속도





출처
쉽게 배우는 알고리즘 | 문병로 | 한빛아카데미 - 예스24
귀납적 사고를 통한 문제 해결 기법 훈련이 책은 알고리즘에 대한 지식을 기반으로 제대로 된 프로그래밍을 하는 이들뿐 아니라, 알고리즘 속에 깃든 여러 가지 생각하는 방법, 자료구조, 테크
www.yes24.com
'Computer Science(컴퓨터 과학) > 알고리즘' 카테고리의 다른 글
| 해시 테이블(Hash Table) (0) | 2025.12.01 |
|---|---|
| 문자열 매칭 알고리즘 - 원시적 방법부터 휴리스틱까지 (0) | 2025.12.01 |
| 동적 프로그래밍(Dynamic Programming) (0) | 2025.11.29 |
| 그리디 알고리즘은 언제 통할까? - 매트로이드로 이해하기 (0) | 2025.11.28 |
| 그리디 알고리즘(Greedy Algorithm)과 그 적용 (0) | 2025.11.28 |








