
해시 테이블(Hash Table)
더 빠른 방법은 없을까?
데이터를 탐색하고, 삭제하고, 저장하는 작업을 가장 빠르게 처리하려면 어떻게 해야 할까? 알고리즘 수업에서 배운 이진 검색 트리는 이런 작업들을 평균 O(log n) 시간에 처리할 수 있는 훌륭한 자료구조다.
하지만 이보다 더 빠른 방법이 있다. 바로 해시 테이블(Hash Table)이다. 해시 테이블은 평균적으로 O(1), 즉 상수 시간에 탐색, 삽입, 삭제를 수행할 수 있다.
이번 글에서는 해시 테이블이 어떻게 이런 놀라운 성능을 내는지, 그리고 실제로 사용할 때 주의해야 할 점은 무엇인지 이야기해보려고 한다.
0. 검색 트리
먼저 검색 트리의 시간 복잡도를 살펴보자.
- 이진 검색 트리(BST): 평균 Θ(log n), 최악 Θ(n)
- 균형 잡힌 이진 검색 트리(AVL, Red-Black Tree 등): 최악 Θ(log n)
- B-트리: 최악 Θ(log n), 균형 잡힌 이진 검색 트리보다 상수 인자가 작음
이들의 공통점은 비교 연산을 통해 탐색한다는 점이다. 아무리 최적화해도 비교 기반 자료구조는 Θ(log n)의 한계를 벗어나기 어렵다. 그렇다면 비교를 하지 않는다면 어떨까? 바로 해시 테이블이 그 답이다.
1. 해쉬 테이블

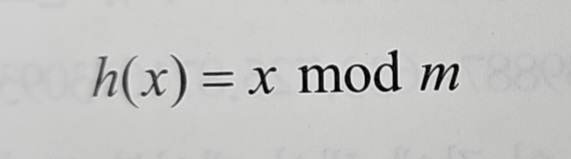
해시 테이블은 원소가 저장될 위치가 원소의 값에 의해 직접 결정되는 자료구조다. 위치는 해시 함수로 계산된다.
위 그림을 예로 들어보자. 해시 테이블의 크기가 13이라면, 해시 함수는 h(x) = x mod 13이 된다. 값 25, 13, 16, 7, 26이 순서대로 들어온다면... (mod는 나머지 연산이다.)
- 25 mod 13 = 12
- 13 mod 13 = 0
- 16 mod 13 = 3
- 7 mod 13 = 7
각 값은 계산된 위치에 바로 저장된다.
탐색도 동일한 방식이다. 25를 찾고 싶다면 25 mod 13 = 12를 계산하고, 12번 위치를 확인하면 된다. 삭제도 마찬가지다. 13을 삭제하려면 13 mod 13 = 0을 계산해 0번 위치에 가서, 값이 13인지 확인한 후 삭제하면 된다.
이런 과정은 단순 계산만으로 이루어지기 때문에 시간 복잡도가 상수 시간 Θ(1)이다.
하지만 단점도 명확하다. 해시 테이블은 최솟값 찾기나 정렬된 순회 같은 순서 기반 연산을 지원하지 않는다. 해시 테이블은 오직 탐색, 저장, 삭제에만 특화된 자료구조라고 생각하면 된다.
2. 해시 함수
해시 함수는 앞서 사용했던 h(x) = x mod m과 같은 형태다. 이 식을 자세히 살펴보자.
- x: 입력되는 키값
- m: 해시 테이블의 크기 (저장 가능한 슬롯의 개수)
- x mod m: 0부터 m-1 사이의 값, 즉 해시 값
예를 들어 m = 13이고 x = 25라면, 25 mod 13 = 12이므로 12번 위치에 저장된다.
좋은 해시 함수를 만들려면 두 가지를 고려해야 한다. 첫째, 값들이 고르게 분산되도록 크기를 정해야 한다. 둘째, 해시 함수 자체가 간단해야 한다.
특히 해시 테이블의 크기 m은 소수로 설정하는 것이 좋다. 소수를 사용하면 입력값들이 더 고르게 분산된다.
해시 함수를 설계하는 방법은 여러 가지가 있지만, 가장 대표적인 것은 나누기 방법과 곱하기 방법이다.
2.1. 나누기 방법(Division Method)

나누기 방법은 키값을 해시 테이블 크기로 나눈 나머지를 사용하는 방식이다.
이 방법에 대한 사용은 이전에 언급했기에 생략하겠다.
2.2. 곱하기 방법(Multiplication Method)

곱하기 방법은 나누기 방법보다 복잡한 형식이다.
- k: 키값
- A: 0과 1 사이의 상수 (보통 황금비 ≈ 0.618을 사용)
- m: 해시 테이블의 크기
- kA mod 1: kA의 소수 부분만 취함 (예: 12.75의 소수 부분은 0.75)
계산 과정은 이렇다.
- 키값 k에 상수 A를 곱한다 (kA)
- 곱한 결과에서 소수 부분만 추출한다 (kA mod 1)
- 소수 부분에 해시 테이블 크기 m을 곱한다
- 결과를 내림하여 정수로 만든다 (⌊ ⌋)
예를 들어 m = 13, A = 0.5로 설정하고 25, 13, 16, 7을 넣어보자.
(여기서는 계산을 간단하게 하기 위해 A = 0.5를 사용했다.)
- h(25) = ⌊13 × (25 × 0.5 mod 1)⌋ = ⌊13 × (12.5 mod 1)⌋ = ⌊13 × 0.5⌋ = 6
- h(13) = ⌊13 × (13 × 0.5 mod 1)⌋ = ⌊13 × (6.5 mod 1)⌋ = ⌊13 × 0.5⌋ = 6 (충돌!)
- h(16) = ⌊13 × (16 × 0.5 mod 1)⌋ = ⌊13 × (8.0 mod 1)⌋ = ⌊13 × 0⌋ = 0
- h(7) = ⌊13 × (7 × 0.5 mod 1)⌋ = ⌊13 × (3.5 mod 1)⌋ = ⌊13 × 0.5⌋ = 4
이 방법은 해시 테이블의 크기 m이 2의 거듭제곱일 필요가 없으며, 나누기 방법보다 m의 선택에 덜 민감하다는 장점이 있다.
3. 충돌 해결
앞서 "충돌"이라는 용어를 사용했다. 충돌이란 무엇일까?
충돌은 서로 다른 키값이 같은 해시 값을 가지는 경우를 말한다. 예를 들어 나누기 방법에서 25와 38 모두 mod 13 = 12가 되어 같은 위치에 저장되려고 할 때 충돌이 발생한다.
충돌을 해결하는 방법은 여러 가지가 있다. 해시 함수 자체를 바꾸는 방법도 있지만, 일반적으로는 충돌 해결 기법을 사용한다. 대표적인 방법으로는 체이닝(Chaining)과 개방 주소법(Open Addressing) 등 여러가지가 있다.
4. 체이닝(chaining)

체이닝은 같은 해시 값을 가진 원소들을 연결 리스트로 연결하여 저장하는 방법이다.
위 그림을 보자. 곱하기 방법에서 25와 13이 모두 해시 값 6을 가졌다. 체이닝은 이들을 6번 위치에 연결 리스트로 묶어서 저장한다.
체이닝의 장점은 삽입과 삭제가 간단하다는 점이다. 연결 리스트의 특성상 원소를 추가하거나 제거하기 쉽다.
하지만 단점도 있다. 만약 80이라는 값의 해시 값이 3이고, 3번 위치에 이미 4개의 원소가 연결되어 있다고 가정하자. 80을 찾으려면 연결 리스트를 따라 최대 4번의 비교가 필요하다. 이는 트리의 연산방식과 다르지 않다. 만약 연결 리스트에 n개가 들어있는 최악의 경우, 선형 탐색을 하는 꼴이 된다.
그럼에도 불구하고 원소들이 고르게 분산되어 있다면 체이닝은 효율적인 충돌 해결 방법이다.
이를 의사코드로 나타내면 다음과 같다.

5. 개방 주소법(Open Addressing)
개방 주소법은 체이닝과 달리 추가 공간을 사용하지 않고 주어진 해시 테이블 내에서 충돌을 해결하는 방법이다.
이 기본 아이디어는 간단하다. 충돌이 발생하면 다른 빈 자리를 찾아 그곳에 저장하는 것이다. 이때 빈 자리를 찾는 방법에 따라 여러 기법으로 나뉜다. 이를 의사코드로 표현하면 다음과 같다.

여기서 $h_i(x)$는 i번째 시도에서 확인할 위치를 계산하는 해시 함수다. 빈 자리를 찾는 방법에 따라 여러 기법으로 나뉘는데, 대표적으로 선형 조사(Linear Probing), 이차 조사(Quadratic Probing), 더블 해싱(Double Hashing)이 있다.
5.1. 선형 조사(Linear Probing)

선형 조사는 충돌이 발생하면 바로 다음 자리를 차례대로 조사하는 방법이다.
$h_i$(x) = (h(x) + i) mod m (그림은 h_j로 설명하지만 h_i가 맞다.)
- i: 충돌 횟수 (0, 1, 2, ...)
- h(x): 원래 해시 값
- m: 해시 테이블 크기
충돌이 발생하면 i를 1씩 증가시키며 빈 자리를 찾는다.
m = 13이고, 해시 함수를 h(x) = x mod 13으로 사용할 때, 25, 13, 16, 15, 7, 28, 31, 20, 1, 38을 순서대로 삽입해보자.
| 키값 | h(x) = x mod 13 | 충돌 여부 | 탐색 과정 | 최종 저장 위치 |
| 25 | 12 | X | 12 | 12 |
| 13 | 0 | X | 0 | 0 |
| 16 | 3 | X | 3 | 3 |
| 15 | 2 | X | 2 | 2 |
| 7 | 7 | X | 7 | 7 |
| 28 | 2 | O | 2→3→4 | 4 |
| 31 | 5 | X | 5 | 5 |
| 20 | 7 | O | 7→8 | 8 |
| 1 | 1 | X | 1 | 1 |
| 38 | 12 | O | 12→0→1→2→3→4→5→6 | 6 |
예를 들어 28은 h(28) = 2지만 2번 위치에 이미 15가 있다. 따라서 다음 위치인 3번을 확인하지만 16이 있어, 그 다음인 4번에 저장된다. 38은 12번에서 시작해 이미 채워진 0, 1, 2, 3, 4, 5를 모두 건너뛰고 6번에 저장된다.
최종 해시 테이블
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 값 | 13 | 1 | 15 | 16 | 28 | 31 | 38 | 7 | 20 | - | - | - | 25 |
* 문제점
위 표를 자세히 보면 문제가 보인다. 만약 이 상태에서 해시 값이 0인 새로운 값을 삽입한다면, 0→1→2→3→4→5→6→7→8까지 총 8번의 탐색이 필요하다.
이처럼 원소들이 한 곳에 모여있는 현상을 군집화(Clustering)라고 한다. 선형 조사에서는 충돌이 발생하면 바로 옆 자리를 확인하기 때문에, 한번 군집이 형성되면 그 군집이 점점 더 커지는 경향이 있다.
군집화는 탐색 시간을 크게 증가시킨다. 최악의 경우 Θ(n)까지 걸릴 수 있어 해시 테이블의 장점인 Θ(1) 성능이 사라진다. 이것이 선형 조사의 가장 큰 문제점이다.
5.2. 이차 조사(Quadratic Probing)

이차 조사는 선형 조사의 군집화 문제를 완화하기 위해 고안되었다. 제곱수만큼 떨어진 자리를 조사하는 방법이다.
hᵢ(x) = (h(x) + c₁ × i² + c₂ × i) mod m
- i: 충돌 횟수 (0, 1, 2, ...)
- c₁, c₂: 상수 (보통 c₁ = 1, c₂ = 0)
- h(x): 원래 해시 값
- m: 해시 테이블 크기
충돌이 발생하면 1², 2², 3², ... 만큼 떨어진 위치를 확인한다.
m = 13이고, 해시 함수를 h(x) = x mod 13, c₁ = 1, c₂ = 0으로 사용할 때, 25, 13, 16, 15, 7, 28, 31, 20, 1, 38을 순서대로 삽입해보자.
| 키값 | h(x) = x mod 13 | 충돌 여부 | 탐색 과정 | 최종 저장 위치 |
| 25 | 12 | X | - | 12 |
| 13 | 0 | X | - | 0 |
| 16 | 3 | X | - | 3 |
| 15 | 2 | X | - | 2 |
| 7 | 7 | X | - | 7 |
| 28 | 2 | O | 2→(2+1)mod 13=3→(2+4)mod 13=6 | 6 |
| 31 | 5 | X | - | 5 |
| 20 | 7 | O | 7→(7+1)mod 13=8 | 8 |
| 1 | 1 | X | - | 1 |
| 38 | 12 | O | 12→(12+1)mod 13=0→(12+4)mod 13=3→(12+9)mod 13=8→(12+16)mod 13=2→(12+25)mod 13=11 | 11 |
최종 해시 테이블
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 값 | 13 | 1 | 15 | 16 | - | 31 | 28 | 7 | 20 | - | - | 38 | 25 |
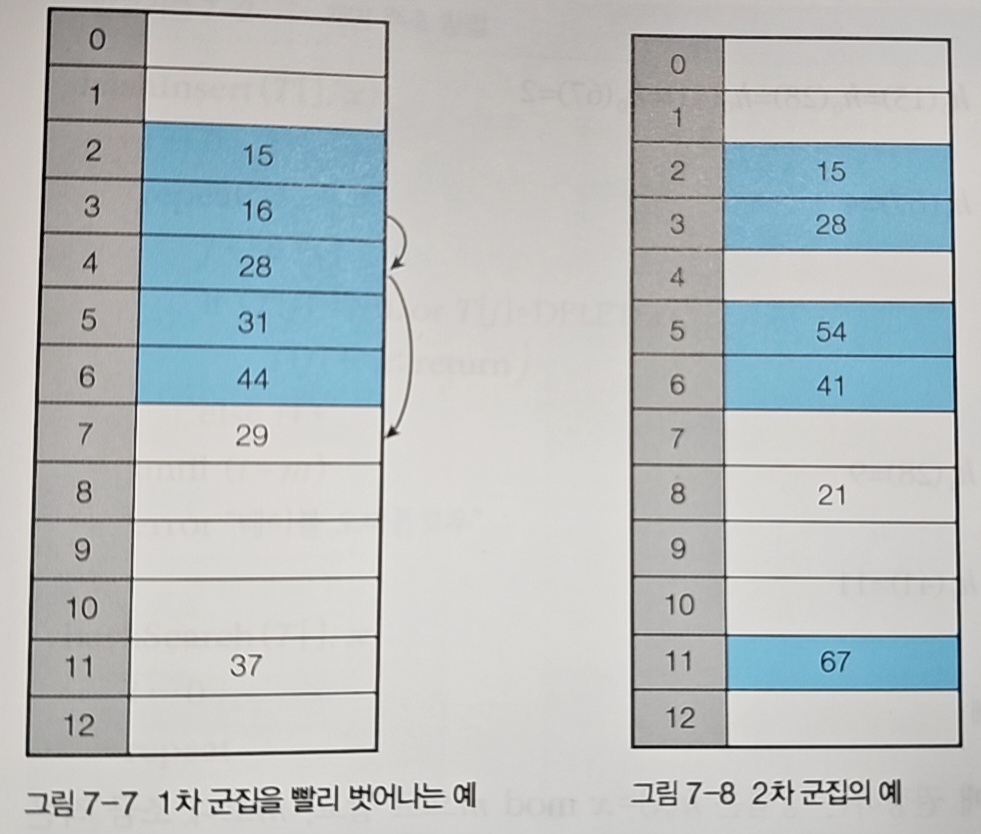
선형 조사와 비교해보자. 선형 조사에서는 0-8번 위치에 9개의 원소가 연속으로 모여 하나의 큰 클러스터를 형성했다. 반면 이차 조사에서는 원소들이 더 고르게 분산되어 있다.
하지만 trade-off가 있다. 38을 삽입할 때 선형 조사는 7번의 위치 확인(12→0→1→2→3→4→5→6)이 필요했지만, 이차 조사는 5번의 확인(12→0→3→8→2→11)이 필요했다.
결론: 이차 조사는 클러스터링은 줄이지만, 개별 원소의 충돌 해결 과정이 길어질 수 있다. 어느 것이 더 나은지는 데이터의 분포와 해시 테이블의 적재율(load factor)에 따라 달라진다.
5.3. 더블 해싱(Double Hashing)


더블 해싱은 두 개의 해시 함수를 사용하여 충돌을 해결하는 방법이다.
- h(x): 첫 번째 해시 함수 (초기 위치 결정)
- f(x): 두 번째 해시 함수 (점프 간격 결정)
- i: 충돌 횟수 (0, 1, 2, ...)
충돌이 발생하면 f(x)만큼 떨어진 위치로 반복적으로 이동한다.
m = 13이고, h(x) = x mod 13, f(x) = 7 - (x mod 7)을 사용할 때, 25, 13, 16, 15, 7, 28, 31, 20, 1, 38을 순서대로 삽입해보자.
| 키값 | h(x) | f(x) | 충돌 여부 | 탐색 과정 | 최종 저장 위치 |
| 25 | 12 | 3 | X | - | 12 |
| 13 | 0 | 1 | X | - | 0 |
| 16 | 3 | 5 | X | - | 3 |
| 15 | 2 | 6 | X | - | 2 |
| 7 | 7 | 7 | X | - | 7 |
| 28 | 2 | 7 | O | 2→(2+7)mod 13=9 | 9 |
| 31 | 5 | 4 | X | - | 5 |
| 20 | 7 | 1 | O | 7→(7+1)mod 13=8 | 8 |
| 1 | 1 | 6 | X | - | 1 |
| 38 | 12 | 3 | O | 12→(12+3)mod 13=2→(12+6)mod 13=5→(12+9)mod 13=8→(12+12)mod 13=11 | 11 |
최종 해시 테이블
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 값 | 13 | 1 | 15 | 16 | - | 31 | - | 7 | 20 | 28 | - | 38 | 25 |
최종 테이블을 보면 클러스터가 2개 존재한다: [0-3]에 4개, [7-9]에 3개. 하지만 선형 조사의 9개짜리 큰 클러스터에 비하면 훨씬 분산되어 있다.
세 가지 방법을 비교해보자
| 기법 | 총 충돌 횟수 | 최대 클러스터 크기 | 38 삽입 시 확인 횟수 |
| 선형 조사 | 3회 | 9개 (0-8번) | 7번 |
| 이차 조사 | 3회 | 작음 (분산됨) | 5번 |
| 더블 해싱 | 3회 | 4개 (0-3번) | 4번 |
더블 해싱은 각 키마다 다른 간격(f(x))으로 점프하기 때문에 클러스터 형성을 더 효과적으로 방지한다. 38의 경우 간격 3으로 점프하면서 비교적 빠르게 빈 자리를 찾았다.
그렇다면 더블 해싱이 항상 최선일까? 꼭 그렇지는 않다. 더블 해싱은 두 개의 해시 함수를 계산해야 하므로 계산 비용이 더 크다. 또한 f(x)가 적절하지 않으면 특정 위치들을 아예 방문하지 못할 수도 있다. 따라서 실제로는 데이터의 특성, 해시 테이블 크기, 적재율 등을 종합적으로 고려해 충돌 해결 방법을 선택해야 한다.
개방 주소법 종합 정리
세 가지 개방 주소법의 특징을 정리하면 다음과 같다.
- 선형 조사: 구현이 가장 간단하고 캐시 지역성(cache locality)이 좋아 실제로는 꽤 빠를 수 있다. 하지만 1차 클러스터링(primary clustering) 문제가 심각하다.
- 이차 조사: 1차 클러스터링은 완화하지만, 같은 해시 값을 가진 키들이 같은 탐색 경로를 따라가는 2차 클러스터링(secondary clustering)이 여전히 존재한다.
- 더블 해싱: 클러스터링을 가장 효과적으로 방지하지만, 두 개의 해시 함수 계산 비용과 f(x) 설계의 복잡성이라는 trade-off가 있다.
개방 주소법의 핵심은 충돌 시 체계적인 규칙에 따라 빈 자리를 탐색하는 것이다. 어떤 기법을 선택할지는 데이터 특성, 성능 요구사항, 구현 복잡도를 종합적으로 고려해야 한다.
5.4. 개방 주소법에서의 삭제
개방 주소법에서 삭제는 단순히 원소를 제거하는 것으로 끝나지 않는다. 그냥 빈 자리로 만들면 탐색 과정에서 문제가 생긴다.
예를 들어 A → B → C 순서로 충돌이 발생해 연속으로 저장되었다고 하자. 만약 B를 삭제하고 빈 자리로 두면, C를 탐색할 때 B 자리에서 탐색이 중단되어 C를 찾지 못한다.
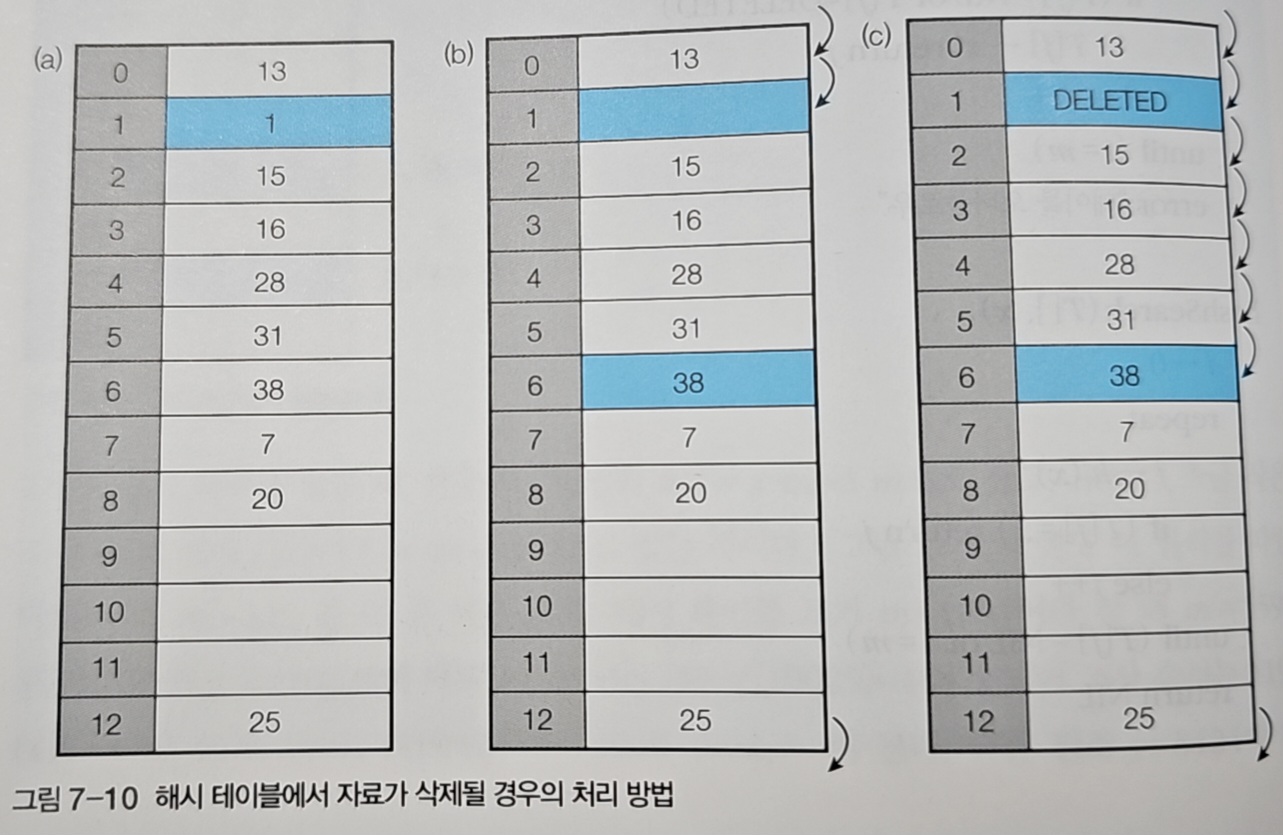
따라서 삭제된 자리에는 DELETED라는 특수 표시를 남긴다. 탐색 시에는 DELETED를 건너뛰고 계속 진행하며, 삽입 시에는 DELETED 자리를 재사용할 수 있다.
이러한 방식은 삭제 연산을 간단하게 만들지만, DELETED 표시가 많아지면 탐색 성능이 저하될 수 있다. 이 경우 주기적으로 해시 테이블을 재구성(rehashing)하여 DELETED 표시를 제거하는 것이 필요하다.
6. 좋은 해쉬 함수란?
지금까지 다양한 충돌 해결 방법을 살펴봤다. 선형 조사는 군집화 문제가 있고, 이차 조사는 충돌 횟수가 늘어나며, 더블 해싱도 완벽하지 않다. 체이닝 역시 최악의 경우 O(n)까지 걸릴 수 있다.
결국 충돌 해결 기법도 중요하지만, 애초에 충돌을 최소화하는 것이 가장 근본적인 해결책이다. 그렇다면 좋은 해시 함수는 어떤 조건을 만족해야 할까?
첫째, 균등 분산(Uniform Distribution)이다. 이상적인 해시 함수는 입력 키들을 해시 테이블의 모든 위치에 고르게 분포시킨다. 특정 영역에 데이터가 몰리면 그 부분에서 충돌이 집중적으로 발생하고, 아무리 좋은 충돌 해결 기법을 사용해도 성능이 저하된다. 균등 분산은 각 슬롯이 선택될 확률을 동일하게 만들어 충돌 가능성 자체를 줄인다.
둘째, 클러스터링(Clustering) 최소화다. 앞서 선형 조사에서 본 것처럼, 한 번 클러스터가 형성되면 그 주변으로 새로운 원소들이 계속 몰리면서 클러스터가 더욱 커진다. 이는 해시 테이블의 평균 성능을 Θ(1)에서 O(n)으로 악화시킬 수 있다. 좋은 해시 함수는 연속된 위치에 원소들이 뭉치는 현상을 방지해야 한다.
셋째, 계산 효율성이다. 해시 함수가 아무리 충돌을 잘 방지하더라도 계산에 오랜 시간이 걸린다면 실용적이지 않다. 해시 테이블의 장점은 빠른 접근 시간인데, 해시 값 계산 자체가 병목이 되면 그 의미가 퇴색된다. 따라서 해시 함수는 단순하면서도 효과적이어야 한다.
결국 좋은 해시 함수는 빠른 계산으로 데이터를 고르게 분산시켜 충돌을 최소화하는 함수다. 이 세 가지 요소 사이의 균형을 찾는 것이 해시 테이블 설계의 핵심이며, 실제로는 테이블 크기를 소수로 선택하거나, 곱셈 해싱, 범용 해싱(universal hashing) 등 다양한 기법을 통해 이를 달성한다.
7. 충돌 해결의 검색 시간 분석
해시 테이블의 성능은 적재율(load factor) α = n/m에 따라 달라진다.
* 체이닝 방법의 실패하는 검색

원소가 없는 경우 평균적으로 α번의 비교가 필요하다.
* 체이닝 방법의 성공하는 검색

원소가 있는 경우 평균적으로 1 + α/2번의 비교가 필요하다.
* 개방 주소 방법의 실패하는 검색

적재율이 높을수록 탐색 시간이 급격히 증가한다.
* 개방 주소 방법의 성공하는 검색

삽입 순서에 따라 성능이 영향을 받는다.
출처
https://www.yes24.com/product/goods/124425168
쉽게 배우는 알고리즘 | 문병로 | 한빛아카데미 - 예스24
귀납적 사고를 통한 문제 해결 기법 훈련이 책은 알고리즘에 대한 지식을 기반으로 제대로 된 프로그래밍을 하는 이들뿐 아니라, 알고리즘 속에 깃든 여러 가지 생각하는 방법, 자료구조, 테크
www.yes24.com
'Computer Science(컴퓨터 과학) > 알고리즘' 카테고리의 다른 글
| 하이퍼그래프(Hypergraph) - 그래프를 확장한 집합적 연결 표현 (0) | 2025.12.14 |
|---|---|
| 상태 공간 트리(State Space Tree) - 백트래킹부터 A*알고리즘까지 (0) | 2025.12.08 |
| 문자열 매칭 알고리즘 - 원시적 방법부터 휴리스틱까지 (0) | 2025.12.01 |
| 집합의 처리를 잘 하는 Union-Find (0) | 2025.11.29 |
| 동적 프로그래밍(Dynamic Programming) (0) | 2025.11.29 |







