
동적 프로그래밍(Dynamic Programming)
수업시간에 피보나치 수열의 50번째 항을 구하는 프로그램을 짜기로 했다. 어떤 사람은 1시간이 지나도 답이 나오지 않았지만, 다른 사람은 1초 만에 문제를 해결했다. 대체 무슨 차이가 있었던 걸까?
1. 재귀적 해법
첫 번째 사람이 사용한 방법은 재귀였다. 피보나치 수는 다음과 같은 점화식으로 정의된다.
f(n) = f(n-1) + f(n-2)
이를 그대로 코드로 옮기면 다음과 같은 의사코드가 나온다.

점화식을 그대로 구현했으니 직관적이고 간결하다. 하지만 실제로 f(7)을 계산하는 과정을 펼쳐보면 문제가 드러난다.


같은 값을 여러 번 계산하고 있다. f(3)은 5번, f(2)는 8번 계산된다. n이 50이 되면? 이 중복은 수백만 번으로 늘어나고, 1시간이 지나도 답이 나오지 않는 상황이 벌어진다.
재귀는 중복 계산이 있을 때 치명적으로 비효율적이다. 반대로 퀵정렬이나 병합정렬처럼 한 번 나눈 문제를 다시 계산하지 않는 경우에는 재귀가 매우 효과적이다.
그렇다면 피보나치처럼 중복이 발생하는 문제는 어떻게 해결할 수 있을까? 바로 동적 프로그래밍이 이를 해결할 수 있다.
2. 동적 프로그래밍
동적 프로그래밍은 큰 문제를 작은 부분 문제로 나누어 풀고, 그 결과를 저장해두었다가 재사용하는 알고리즘 기법이다.
동적 프로그래밍은 최적 부분 구조(Optimal Substructure) 를 가진 문제에서 유용하다. 최적 부분 구조란 큰 문제의 최적해가 작은 부분 문제의 최적해로 구성되는 구조를 의미한다.
피보나치 수열을 다시 보자. f(7)을 구하려면 f(6)과 f(5)가 필요하고, f(6)을 구하려면 f(5)와 f(4)가 필요하다. 큰 문제가 작은 문제들의 답으로 이루어져 있다. 바로 최적 부분 구조다.
그렇다면 한 번 계산한 f(5)를 어딘가에 저장해두고, 다음에 필요할 때 다시 꺼내 쓰면 어떨까? 중복 계산이 사라지고 실행 시간이 극적으로 줄어들 것이다.
3. 동적 프로그래밍의 유형
그럼 피보나치 수열을 동적 프로그래밍으로 어떻게 풀 수 있을까?
작은 값부터 차례대로 계산해 배열에 저장하는 방법을 생각해볼 수 있다.

f[2]부터 f[n]까지 순서대로 계산하면서 배열에 저장한다. 필요한 값(f[i-1], f[i-2])은 이미 계산되어 있으니 바로 꺼내 쓰면 된다.
for문을 n번 돌기 때문에 시간 복잡도는 O(n) 이다. 재귀 방식의 지수 시간과 비교하면 엄청난 개선이다.
그런데 재귀 방식도 개선할 수는 없을까?
앞서 본 재귀 코드를 다시 보자.
문제는 같은 값을 계속 다시 계산한다는 점이다. f(7)을 계산하려면 f(5)를 호출하고, f(6)을 계산할 때도 또 f(5)를 호출한다. 이미 한 번 계산한 f(5)를 버리고 처음부터 다시 계산하는 것이다.
만약 한 번 계산한 f(5)를 어딘가에 저장해두고 재사용한다면? 재귀의 직관성은 유지하면서 중복 계산만 제거할 수 있지 않을까?

위 의사코드는 재귀를 유지하면서 중복 계산을 제거하는 방법이다.
fib(i)를 실행할 때마다 계산 결과를 f[i]에 저장한다. 다음에 fib(i)가 다시 호출되면 재계산 없이 저장된 값을 바로 반환한다. 이렇게 하면 같은 값을 여러 번 계산하는 비효율을 완전히 제거할 수 있다.
우리는 전자를 상향식(Bottom-up) 방법이라고 부르며, 후자를 하향식(Top-down) 방법이라고 부른다.
간단하게 상향식은 아래에서 위로 저장해 가면서 해를 계산하는 방법, 하향식은 재귀 호출을 사용하되 한 번 호출된 것은 메모해 둠으로 중복 호출을 제거하는 방법으로 알고 있으면 좋다.
3.1. 상향식 vs 하향식 햇갈리는 점
여기서 헷갈리기 쉬운 점이 있다. "하향식도 결국 f(1), f(2), f(3)... 순서로 계산되는 거 아닌가?"라고 생각할 수 있다. 맞다. 실제 계산 순서는 작은 값부터 이루어진다.
하지만 '어디서부터 문제를 바라보느냐'가 다르다.
상향식은 "f(1), f(2)부터 차례로 계산해서 f(50)까지 가자"라는 접근이다. 기저 사례에서 시작한다.
반면 하향식은 "f(50)을 구하려면 뭐가 필요하지? f(49)와 f(48)이네. 그럼 f(49)를 구하려면...?"이라는 접근이다. 목표 값에서 시작해서 필요한 것을 찾아 내려간다. 비록 실제 계산은 재귀가 가장 깊이 들어간 후 돌아오면서 이루어지지만, 문제를 푸는 사고의 방향이 위에서 아래로 향한다는 점에서 하향식이다.
구체적으로 f(5)를 구하는 과정을 비교해보자.
상향식 (Bottom-up)
시작: f(0), f(1)
↓
f[0] = 0
f[1] = 1
↓
f[2] = f[0] + f[1] = 1
↓
f[3] = f[1] + f[2] = 2
↓
f[4] = f[2] + f[3] = 3
↓
f[5] = f[3] + f[4] = 5 ✓ (목표 도달)
진행 방향: 아래(기저)에서 → 위(목표)로
하향식 (Top-down)
[문제 분해 단계: 위에서 아래로]
fib(5) 호출
├─ fib(4) 필요
│ ├─ fib(3) 필요
│ │ ├─ fib(2) 필요
│ │ │ ├─ fib(1) = 1 ✓
│ │ │ └─ fib(0) = 0 ✓
│ │ └─ fib(1) = 1 ✓
│ └─ fib(2) = 1 (이미 계산됨, 메모에서 가져옴)
└─ fib(3) = 2 (이미 계산됨, 메모에서 가져옴)
[계산 완료 단계: 아래에서 위로]
fib(2) = 1 계산 → 메모 저장
fib(3) = 2 계산 → 메모 저장
fib(4) = 3 계산 → 메모 저장
fib(5) = 5 계산 완료! ✓
핵심: "fib(5)를 구하려면?" → 필요한 걸 찾아 내려감 (Top-down)
실제 계산은 맨 아래서부터 올라오며 진행됨
이 중 실제로 무엇이 좋은 지는 상황에 따라 달라지기에 목적에 맞게 알맞는 방법을 쓰는게 요구된다.
4. 동적 프로그래밍의 예
피보나치만으로는 동적 프로그래밍의 진가를 보기 어렵다. 최적 부분 구조를 만족하는 다른 문제들을 살펴보며 동적 프로그래밍의 활용법을 익혀보자.
4.1. 행렬 경로 문제

행렬 경로 문제는 행렬의 왼쪽 위에서 시작해 오른쪽 아래까지 이동하면서, 오른쪽이나 아래로만 이동할 수 있는 조건으로, 지나간 칸의 점수를 모두 더했을 때 합이 최소가 되는 경로를 찾는 문제다.
생각해보면 어떤 칸에 도달했을 때, 그 시점까지의 경로가 최적이어야 한다. 이 조건은 문제를 작게 나누어도 똑같이 성립한다. 바로 최적 부분 구조다.
이를 수식으로 나타내보자.
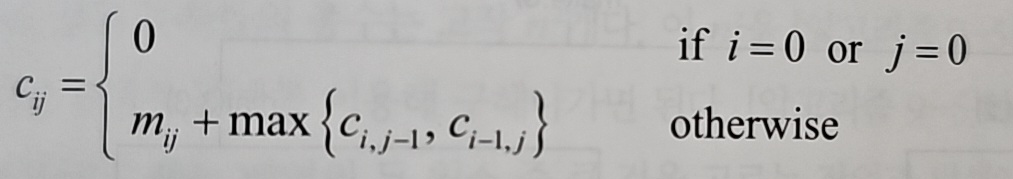
여기서 c[i][j]는 (i, j)까지의 최소 비용, m[i][j]는 해당 칸의 점수다.
이를 그대로 의사코드로 작성하면 다음과 같다.


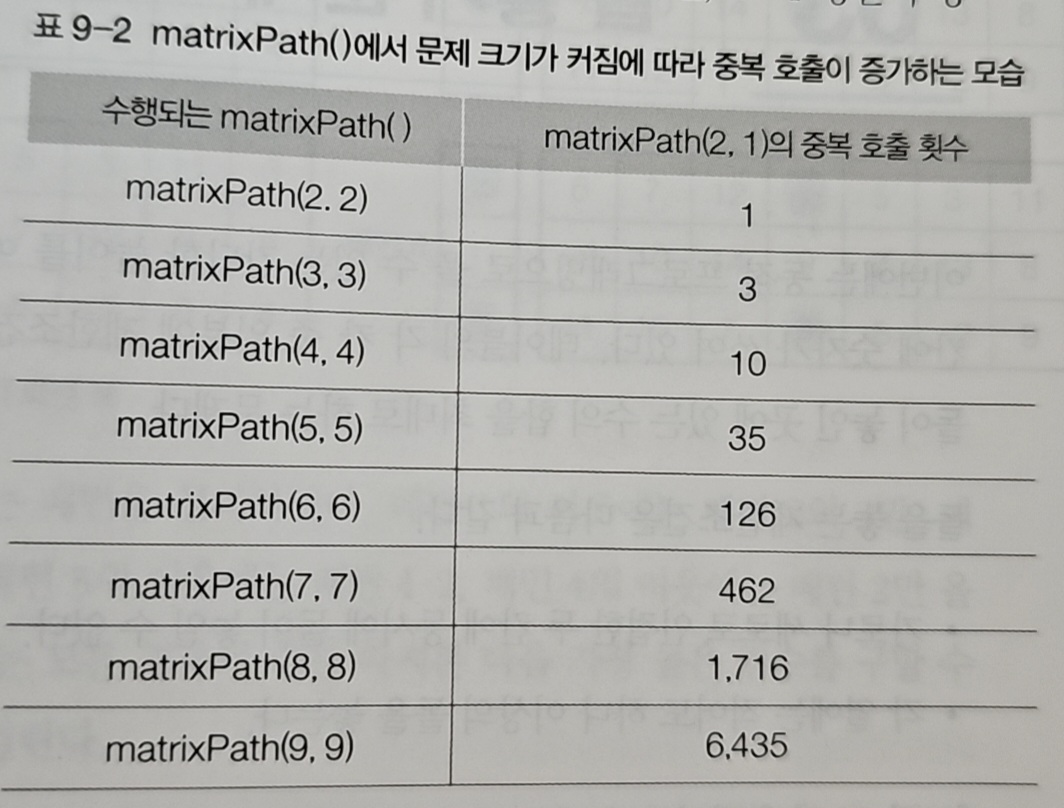
하지만 같은 칸을 여러 번 중복 계산하는 문제가 발생한다.
이럴 때 필요한 것이 동적 프로그래밍이다. 중복 계산을 제거해보자.

하향식 방법을 사용했다. 계산한 c[i][j] 값을 배열에 저장해두고, 다음에 같은 칸이 필요하면 재계산 없이 저장된 값을 바로 반환한다. 이렇게 풀면 O(n²) 시간에 해결할 수 있다. 재귀적 방법의 O(2ⁿ)과 비교하면 엄청난 차이다.
4.2. 돌 놓기 문제

더 어려운 문제를 알아보자.
돌 놓기 문제는 3 × N 크기의 테이블이 주어지고, 각 칸에는 양수 또는 음수가 적혀 있다. 이 테이블에 돌을 놓되, 돌이 놓인 칸의 숫자 합이 최대가 되도록 배치하는 문제다.
단, 두 가지 조건이 있다. 첫째, 가로나 세로로 인접한 두 칸에는 동시에 돌을 놓을 수 없다. 둘째, 각 열에는 반드시 하나 이상의 돌을 놓아야 한다.
이 문제를 어떻게 풀어야 할까? N이 커지면 모든 경우의 수를 따져보는 것은 불가능하다. 하지만 각 열에서 가능한 돌의 배치 패턴을 생각해보면 실마리가 보인다.
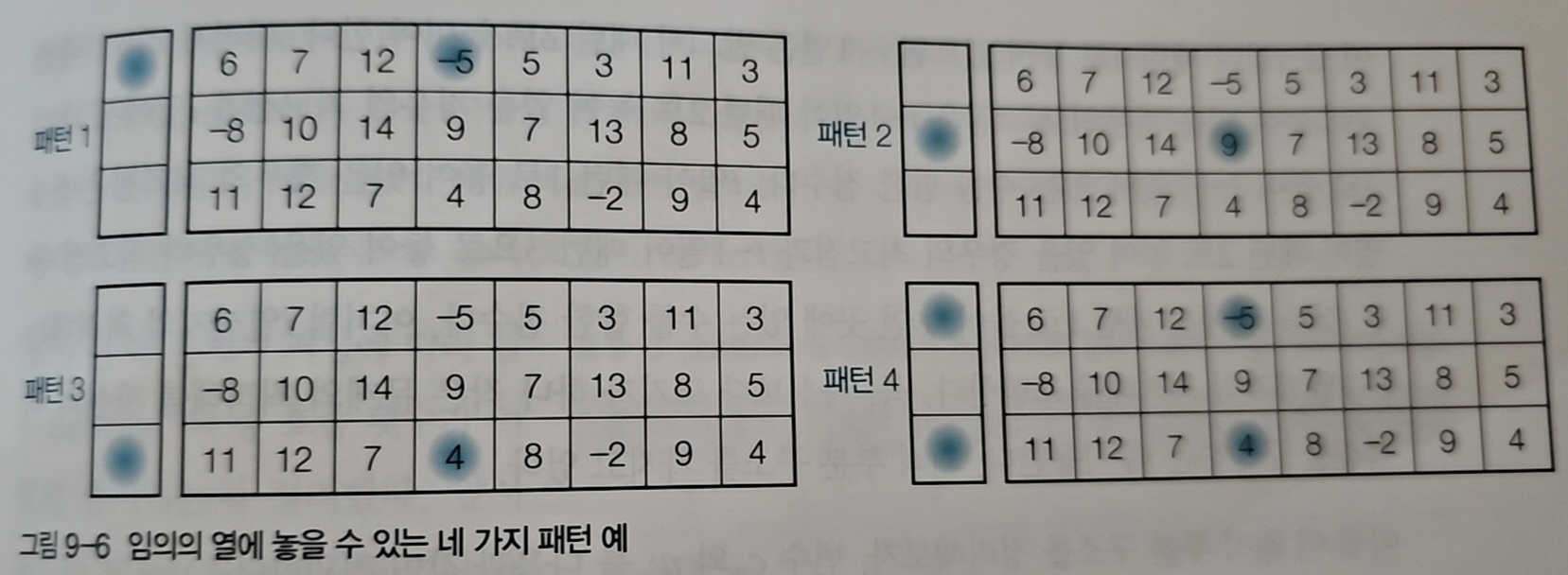

조건을 만족하는 패턴은 총 4가지다. 각 열은 이 4개 패턴 중 하나를 선택해야 한다. 그렇다면 각 단계에서 4가지 패턴 중 가장 높은 점수를 내는 것을 선택하면서 진행하면 된다. 문제를 패턴별로 나누면 최적 부분 구조가 된다.
이를 재귀식으로 나타내면 다음과 같다.

이를 의사코드로 작성하면 다음과 같다.

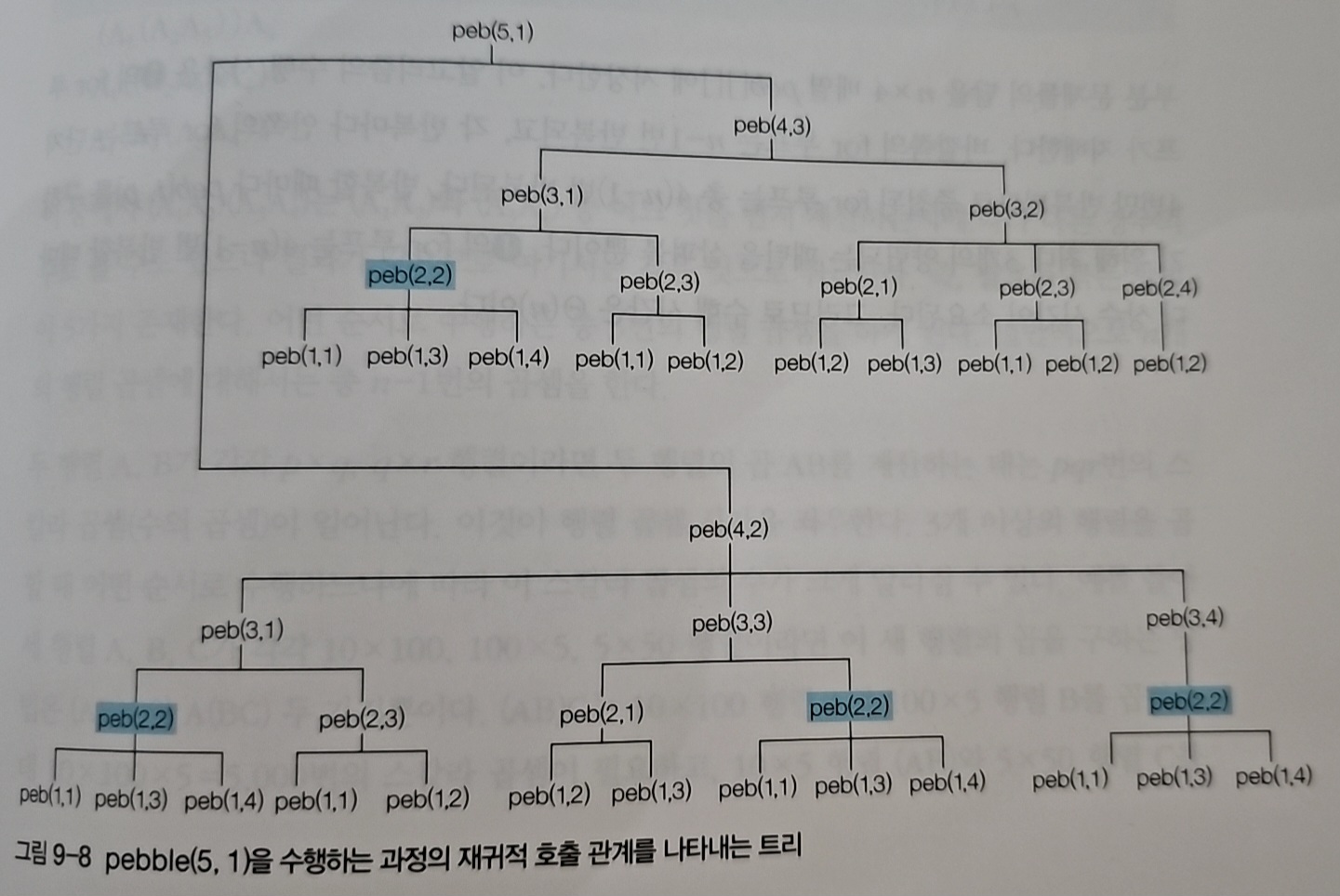

역시 중복 계산이 발생한다. 동적 프로그래밍을 적용해보자.

peb[][] 배열에 계산한 값을 저장하고, 같은 상태가 다시 필요하면 저장된 값을 바로 반환한다. 중복 계산이 제거되면서 효율적으로 문제를 해결할 수 있다.
4.3. 행렬 곱셈 순서 문제
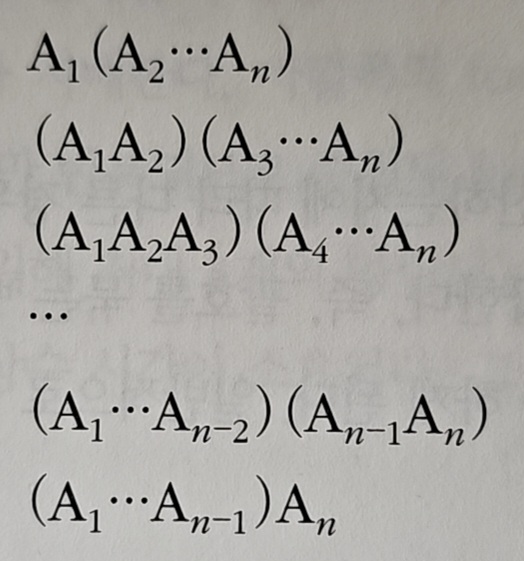
행렬 곱셈 순서 문제는 3개 이상의 행렬을 곱할 때, 어떤 순서로 곱하느냐에 따라 계산량이 달라지는데 이를 최소화하는 문제다.
예를 들어 A(10×100), B(100×5), C(5×50) 세 행렬이 있다고 하자.
(AB)C로 계산하면 10×100×5 + 10×5×50 = 7,500번의 곱셈이 필요하다. 반면 A(BC)로 계산하면 100×5×50 + 10×100×50 = 75,000번의 곱셈이 필요하다. 무려 10배 차이다.
그렇다면 모든 경우를 일일이 확인해봐야 할까? 위 그림은 n개의 행렬이 있을 때 가능한 모든 곱셈 순서를 나타낸 것이다. 경우의 수가 너무 많다.
하지만 이 문제를 재귀식으로 나타내는 것은 어렵지 않다.

식 $(A_i...A_j)$를 $(A_i... A_k)(A_{k+1}...A_j)$로 나눈다. $C_{ik}$를 $(A_i... A_k)$를 곱하는 최소 비용,
$C_{k+1,i}$를 $(A_{k+1}...A_J)$를 곱하는 최소 비용이라 하자. 그리고 $p_{j-1} p_k p_j$를 $(A_i... A_k)(A_{k+1}...A_J)$ 를 두 결과 행렬을 곱하는 비용이라 하면, 이들의 합 중 최솟값이 답이 된다.
이를 의사코드로 작성하면 다음과 같다.

하지만 재귀식의 시간복잡도는 O(2^n)으로 매우 비효율적이다. 동적 프로그래밍을 적용해보자.

m[i][j]에 i번째부터 j번째 행렬까지 곱하는 최소 비용을 저장한다. 중복 계산이 사라지면서 시간복잡도가 크게 개선된다. m[i][j]를 구하는 데 O(n)이 걸리고, 이런 칸이 n^2개 있으므로 전체 시간복잡도는 O(n^3)이다.
4.4. 최장 공통 부분 순서(LCS, Longest Common Subsequence)
최장 공통 부분 순서 문제는 두 문자열에서 공통적으로 나타나는 가장 긴 부분 순서를 찾는 문제다.
여기서 부분 순서란 문자열에서 일부 문자를 순서대로 뽑아낸 것을 말한다. 예를 들어 문자열 <abcbdab>에서 <bcdb>는 부분 순서다. 문자들이 원래 순서를 유지하면서 추출되었기 때문이다.
공통 부분 순서는 두 문자열 모두에서 나타나는 부분 순서를 의미한다. 예를 들어 <bca>는 문자열 <abcbdab>와 <bdcaba> 모두의 부분 순서이므로 공통 부분 순서다.
이 문제를 풀기 위한 핵심 원리를 정리하면 다음과 같다.

이를 재귀식으로 나타내면 다음과 같다.

이를 의사코드로 작성하면 다음과 같다.

여기도 마찬가지다. 역시 중복 계산이 발생한다.
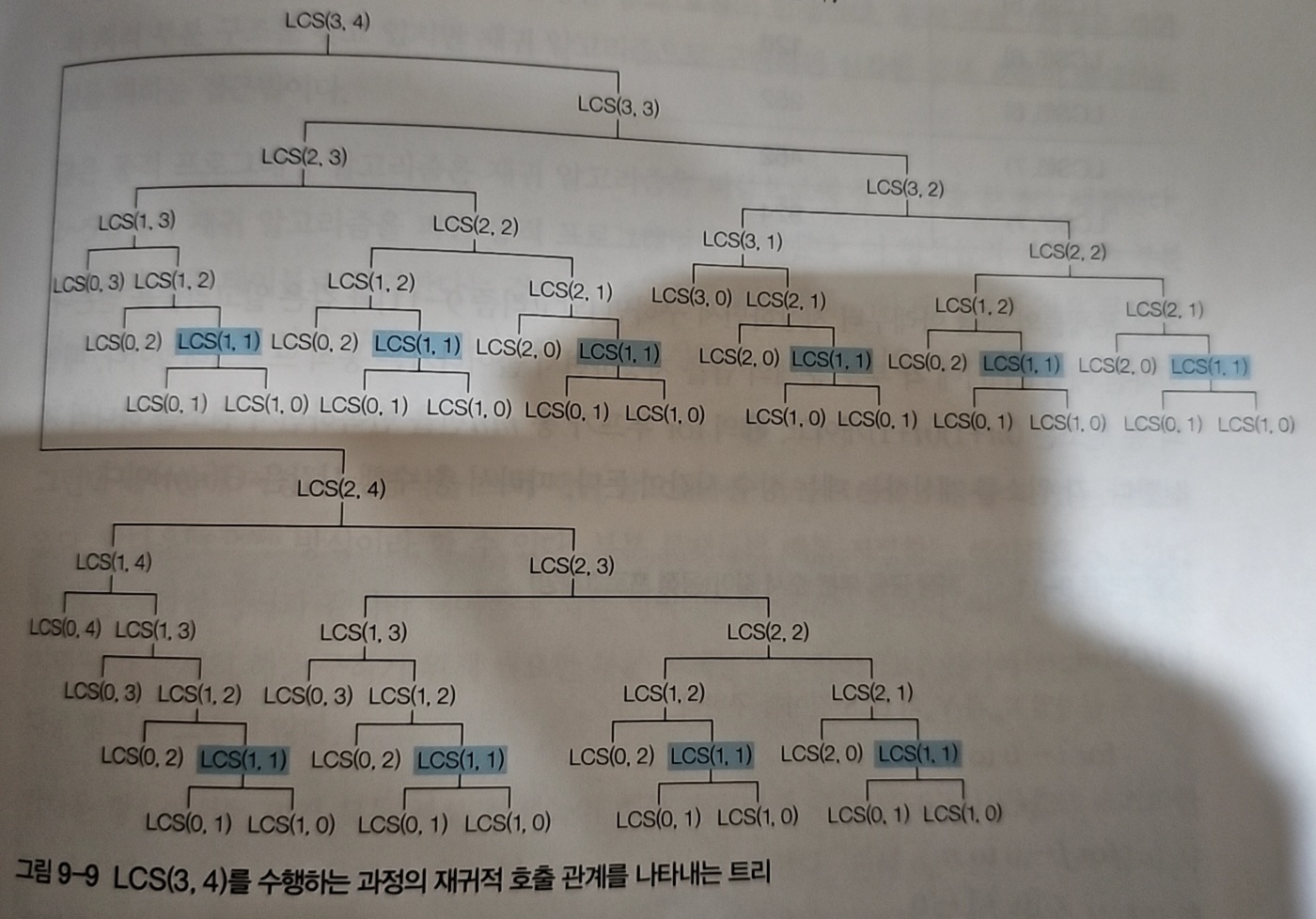

동적 프로그래밍을 적용해보자.

이번 방법도 이차원 배열 C[][]에 각 부분 문제의 계산을 저장하는 방식으로 하였다.
배열의 크기는 (m+1)×(n+1)이고, for 루프가 mn번 반복하면서 각 칸을 계산한다. 따라서 시간복잡도는 O(mn)이다.
5. 메모하기(Memolization)
지금까지 여러 문제를 풀어보며 공통된 패턴을 발견할 수 있었다. 최적 부분 구조를 가진 문제는 재귀식으로 자연스럽게 표현된다. 하지만 단순 재귀는 같은 계산을 반복하며 비효율적이다.
이 비효율을 해결하는 핵심이 바로 한 번 계산한 값을 저장해두고 재사용하는 것이였다.
앞서 본 상향식 방법은 작은 값부터 차례로 계산하며 배열을 채워나갔다. f(1), f(2), f(3)... 순서대로 계산해서 나중에 f(50)을 구할 때 필요한 값들이 이미 준비되어 있는 방식이다.
반면 메모이제이션은 반대로 접근한다. f(50)을 계산하려면 f(49)가 필요하고, f(49)를 계산하려면 f(48)이 필요하다. 이렇게 필요한 값을 위에서부터 내려가며 계산하고, 한 번 계산한 값은 메모해둔다. 다음에 같은 값이 또 필요하면 재계산 없이 메모에서 꺼내 쓴다. 이것이 하향식 접근법이다.

가장 대표적으로 피보나치 수열을 다시 확인해보자. 이전 상향식에서는 f[1]부터 시작해서 f[2], f[3]... 순서대로 계산했다.
하지만 하향식 방법을 보자. f[n] ← fib(n-1) + fib(n-2) 코드에서 fib(50)을 호출하면 어떻게 될까?
처음 이를 접하는 사람은 "fib(50)에서 바로 계산이 끝나는 거 아닌가?"라고 생각할 수 있다. 하지만 그렇지 않다. fib(50)을 계산하려면 fib(49)와 fib(48)이 필요하고, fib(49)를 계산하려면 또다시 fib(48)과 fib(47)이 필요하다. 이렇게 필요한 값을 찾아 계속 내려간다.
결국 fib(1)과 fib(0)까지 도달하면, 이제 거꾸로 올라오면서 값들이 하나씩 계산된다. fib(2), fib(3), fib(4)... 순서대로 채워지면서 최종적으로 fib(50)의 값이 완성된다. 단, 한 번 계산한 값은 메모에 저장되어 있어서 중복 계산은 일어나지 않는다.
하향식(메모이제이션)은 실제로 호출되는 경우만 계산하므로, 불필요한 계산을 건너뛸 수 있다.
아래 방법들은 메모이제이션으로 구하는 방법을 설명하고 있다. 하향식(메모이제이션)은 큰 문제에서 시작해 필요한 작은 문제들을 계산하며, 상향식은 작은 문제부터 순차적으로 계산한다.



이번에는 동적 프로그래밍을 배웠다. 이 방법은 알고리즘 역사에서 매우 중요한 위치를 차지한다. 같은 하드웨어로도 실행 시간을 몇 시간에서 몇 초로 줄일 수 있게 해준, 컴퓨터 성능을 극적으로 끌어올린 기법 중 하나이기 때문이다.
하지만 모든 문제가 동적 프로그래밍으로 풀리는 것은 아니다. 동적 프로그래밍이 효과를 발휘하려면 중복되는 부분 문제가 존재해야 하며, 재귀적(점화식) 문제로 변환할 수 있어야 한다. 예를 들어 정렬 알고리즘은 각 단계에서 서로 다른 작업을 수행하기 때문에 동적 프로그래밍을 적용할 수 없다.
결국 중요한 것은 문제를 보고 "이 문제에 중복 계산이 있는가? 최적 부분 구조를 만족하는가?"를 판단하는 능력이다. 그 판단이 서면, 동적 프로그래밍은 강력한 무기가 되어줄 것이라 믿는다.
출처
쉽게 배우는 알고리즘 | 문병로 | 한빛아카데미 - 예스24
귀납적 사고를 통한 문제 해결 기법 훈련이 책은 알고리즘에 대한 지식을 기반으로 제대로 된 프로그래밍을 하는 이들뿐 아니라, 알고리즘 속에 깃든 여러 가지 생각하는 방법, 자료구조, 테크
www.yes24.com
'Computer Science(컴퓨터 과학) > 알고리즘' 카테고리의 다른 글
| 문자열 매칭 알고리즘 - 원시적 방법부터 휴리스틱까지 (0) | 2025.12.01 |
|---|---|
| 집합의 처리를 잘 하는 Union-Find (0) | 2025.11.29 |
| 그리디 알고리즘은 언제 통할까? - 매트로이드로 이해하기 (0) | 2025.11.28 |
| 그리디 알고리즘(Greedy Algorithm)과 그 적용 (0) | 2025.11.28 |
| 강연결 요소(Strongly Connected Component, SCC) (0) | 2025.11.27 |








