
최소 신장 트리와 프림(Prime), 크루스칼(Kuskal) 알고리즘
머리로는 "가장 짧은 것들만 골라서 연결하면 되지 않을까?" 싶지만, 막상 해보면 어디서부터 시작해야 할지, 이게 정말 최선인지 확신이 서지 않는다. 도시가 10개만 넘어가도 손으로 푸는 건 사실상 불가능하다.
다행히도 이런 최소 신장 트리 문제를 해결하는 깔끔한 알고리즘이 있다. 바로 프림과 크루스칼이다. 이번 글에서는 이 둘 알고리즘에 대해서 이야기해보도록 하겠다.
1. 최소 신장 트리(Minimum Spanning Tree, MST)
본격적으로 알고리즘을 보기 전에, 우리가 풀려는 문제부터 정리하자. 목표는 모든 도시를 연결하되, 전선 비용을 최소화하는 것이다.
 |
→
|
 |
 |
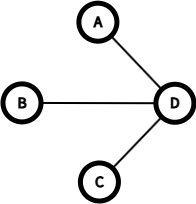 |
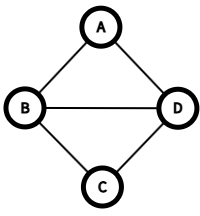
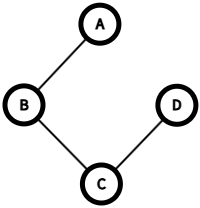
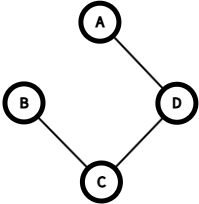
위 그림을 보면, 원래 복잡한 그래프에서 필요 없는 간선들을 제거하고 핵심만 남겼다. 이렇게 모든 정점을 연결하되 사이클 없이 연결한 구조를 신장 트리(Spanning Tree)라고 한다.
n개의 정점이 있다면 정확히 n-1개의 간선만 있으면 된다. 더 많으면 사이클이 생기고, 더 적으면 모든 정점을 연결할 수 없다.
그런데 하나의 그래프에서 만들 수 있는 신장 트리는 여러 개다. 이 중에서 간선들의 가중치 합이 최소인 것이 바로 최소 신장 트리(Minimum Spanning Tree, MST)다.
2. 프림(Prim) 알고리즘
프림 알고리즘의 핵심은 간단하다. 현재 트리와 연결된 간선들 중 가장 가벼운 것을 반복해서 선택하는 것이다.
2.1. 동작 원리
즉, 이 알고리즘은 그리디(Greedy) 방식의 알고리즘이다. 그 동작 원리는 다음과 같다.
1) 아무 정점 하나를 골라서 시작한다
2) 현재 트리와 연결할 수 있는 간선 중 가장 가벼운 것을 고른다
3) 그 간선으로 새 정점을 트리에 추가한다
4) 모든 정점이 들어올 때까지 반복한다
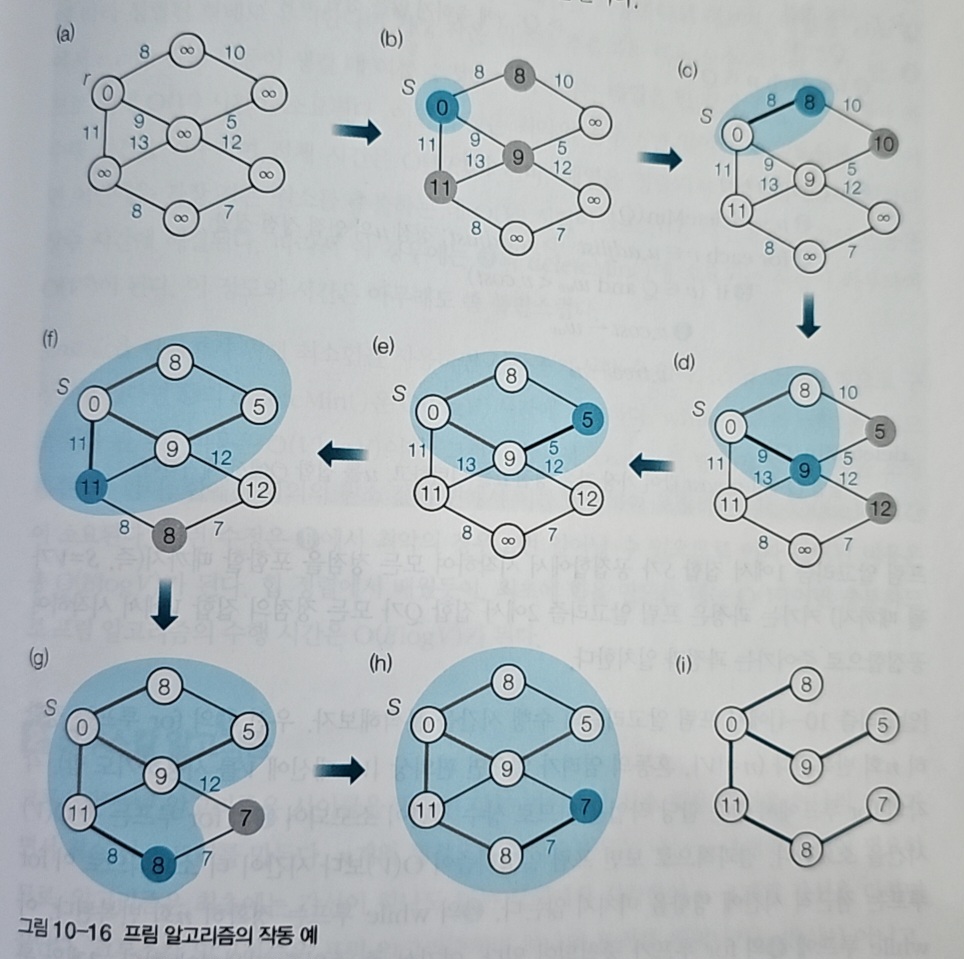
위 그림을 보면 이해가 쉽다. 파란색으로 표시된 부분이 현재까지 만들어진 트리고, 매 단계마다 여기서 가장 가까운(가중치가 작은) 정점을 하나씩 끌어들인다.
2.2. 구현
프림 알고리즘의 구현 핵심은 두 가지다.
1) 집합 S를 공집합으로 시작해서 모든 정점을 포함할 때까지 반복
2) 매번 "아직 S에 없으면서 cost가 최소인 정점"을 빠르게 찾기
여기서 2번을 효율적으로 하기 위해 "우선순위 큐"를 쓰도록 하겠다.
우선 순위순위 큐는 힙으로 구현이 가능하며, 우선 순위가 큰 순서대로 빠져 나가는 구조를 의미한다.
import heapq
def prim(graph, start):
S = set() # 현재까지 만들어진 트리에 포함된 정점들
V = set(graph.keys()) # 그래프의 모든 정점
# cost[정점]: 그 정점을 트리에 추가하는 데 드는 최소 비용을 의미
cost = {u: float("inf") for u in V} # 계산할 때를 생각하여 무한대로 정해둠
cost[start] = 0 # 시작은 0
# tree[정점]: 그 정점이 어느 정점을 통해 트리에 추가되었는지 기록
# 나중에 "A-C, C-B, B-D" 같은 간선 정보를 만들기 위해 필요
tree = {u: None for u in V}
# min_heap: "다음에 추가할 수 있는 정점들"
# (비용, 정점) 형태로 저장하면 자동으로 비용 순으로 정렬됨
min_heap = [(0, start)] # 처음 내용을 넣기 어렵기에 이렇게 초기화를 해주었다.
# 모든 정점을 트리에 추가할 때까지 반복
while len(S) != len(V):
# 1단계: 아직 트리에 없는 정점 중 비용이 가장 작은 것을 찾기
u = extractMin(min_heap, S)
if u is None: # 더 이상 추가할 정점이 없으면 종료
break
# 2단계: 선택한 정점 u를 S에 추가
S.add(u)
# 3단계: 새로 추가된 정점 u에 정점들을 찾아서 갱신
for v, w_uv in graph[u]: # u와 연결된 모든 정점 v, 가중치에 대해서
# v가 아직 트리에 없고, u를 거쳐가는 게 더 싸다면
if v not in S and w_uv < cost[v]:
# v의 "트리에 추가하는 최소 비용"을 갱신
cost[v] = w_uv
# "v는 나중에 u를 통해 트리에 들어온다"고 기록
tree[v] = u
# 갱신된 정보를 힙에 추가 (나중에 v를 선택할 수 있도록)
heapq.heappush(min_heap, (w_uv, v))
# 결과 계산
total_cost = sum(cost[v] for v in V if tree[v] is not None)
mst_edges = [(tree[v], v, cost[v]) for v in V if tree[v] is not None]
return total_cost, mst_edges
def extractMin(min_heap, S):
# 아직 트리에 추가되지 않은 정점 중 비용이 최소를 반환
while min_heap:
cost_val, u = heapq.heappop(min_heap)
if u not in S: # 아직 트리에 추가되지 않은 정점 반환
return u
return None
test_graph = {
'A': [('B', 4), ('C', 1)],
'B': [('A', 4), ('C', 2), ('D', 5)],
'C': [('A', 1), ('B', 2), ('D', 8)],
'D': [('B', 5), ('C', 8)]
}
total, edges = prim(test_graph, 'A')
print(f"최소 비용: {total}")
print("\nMST 간선:")
for parent, node, weight in edges:
print(f" {parent} → {node}: {weight}")
실제 구현은 여러가지 생각할 내용이 많아 어렵지만, 핵심은 S집합, cost에 값을 저장하면서, 이을 수 있는 노드들 중에 가장 작은 가중치를 찾아서 트리를 만드는 것에 있다. 이를 위해서 우선순위 큐와 같은 얘들을 사용했다고 보면 된다.
하지만, 프림 알고리즘은 집합을 추적하는 관점을 바꿔서 구현할 수도 있다.
기존 방식: S 집합(트리에 포함된 정점)을 ∅에서 시작해 V로 확장
역방향 방식: Q 집합(아직 트리에 안 들어간 정점)을 V에서 시작해 ∅로 축소
두 방식의 차이는 "어느 집합을 추적하느냐"일 뿐, 알고리즘의 본질은 동일하다.
Q = V - S 관계이므로, S가 커지면 Q가 작아진다.
3. 크루스칼(Kruskal) 알고리즘
프림 알고리즘은 노드 중심이였다. 한 정점에서 시작해서 트리를 점진적으로 확장했다.
하지만 크루스칼은 접근이 다르다. 엣지 중심으로 작동하며, 가중치가 작은 간선부터 차례대로 선택하는 전략을 사용한다.
3.1. 동작 원리
크루스칼도 그리디 알고리즘이다.
하지만 프림과 다른 점은 다음과 같다.
1) 모든 간선을 가중치 순으로 정렬
2) 가장 작은 간선부터 하나씩 선택
3) 사이클을 만들지 않으면 MST에 추가
4) n-1개의 간선을 선택할 때까지 반복
위 그림을 보면, 프림처럼 하나의 연결된 트리가 자라는 게 아니라, 여러 개의 작은 트리들이 점점 합쳐지는 모습이다.
3.2. 구현
크루스칼 알고리즘을 구현하려면 사이클을 감지할 수 있어야 한다. 간선을 추가할 때 다음의 규칙을 사용한다.
1) 간선 (u, v)를 추가할 때, u와 v가 이미 같은 트리에 속해 있으면 → 사이클 발생! (추가하면 안 됨)
2) 간선 (u, v)를 추가할 때, u와 v가 다른 트리에 속해 있으면 → OK! (두 트리를 합침)
문제는 "두 정점이 같은 트리에 속하는지" 어떻게 빠르게 판단하느냐다. 이를 위해 Union-Find(합집합 찾기) 자료구조를 사용한다. Union-Find는 서로소 집합을 관리하며 Find로 같은 트리 여부를, Union으로 트리 합치를 효율적으로 수행하는 자료구조다.
[알고리즘] Union-Find 알고리즘 - Heee's Development Blog
Step by step goes a long way.
gmlwjd9405.github.io
(Union-Find에 대한 내용을 쉽게 설명한 내용이 있어 올린다.)
1) Union-Fine 구현
# 예로 들어 [A, B], [C, D, E, F]가 있다고 하자
# 그냥 집합은 이것들을 같은 걸로 본다. 이를 없애기 위해 구분해주는 게 필요하다.
# 그렇기에 이를 효과적으로 도와주는 자료구조가 필요해서 UnionFind를 썼다고만 이해하자.
class UnionFind:
def __init__(self, elements):
self.parent = {x: x for x in elements}
self.rank = {x: 0 for x in elements}
def find(self, x):
# 경로 압축: 루트를 찾으면서 경로상의 모든 노드를 루트에 직접 연결
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x])
return self.parent[x]
def union(self, x, y):
# 각 원소의 루트를 찾아야 함
x_root = self.find(x)
y_root = self.find(y)
# 이미 같은 집합이면 False 반환 (사이클 발생)
if x_root == y_root:
return False
# Union by Rank: 랭크가 작은 트리를 큰 트리 밑에 붙임
if self.rank[x_root] < self.rank[y_root]:
self.parent[x_root] = y_root
else:
self.parent[y_root] = x_root
# 두 루트의 랭크가 동일하면, 두 트리를 합칠 때 트리의 실제 높이가 1 증가하므로
# 새 루트(x_root)의 랭크를 높여 트리 높이를 정확히 반영한다
if self.rank[x_root] == self.rank[y_root]:
self.rank[x_root] += 1
return True
2) 크루스칼 알고리즘 구현
def kruskal(graph):
edges = []
for u in graph:
for v, w in graph[u]:
if (v, u, w) not in edges: # 중복 간선 제거를 위함
edges.append((u, v, w))
edges.sort(key=lambda x: x[2]) # 가중치를 오름차순으로 정렬
uf = UnionFind(graph.keys())
mst = []
total_cost = 0
for u, v, w in edges: # 본격적으로 알고리즘 시작
if uf.union(u, v): # union으로 앞에서부터 연결.
mst.append((u, v, w)) # 동시에 mst를 추가하는데 이것은 연결된 간선을 추적하는데 쓴다.
total_cost += w # cost도 증가
if len(mst) == len(graph) - 1: # 추적하는 데 씀
break
return total_cost, mst
# 테스트 그래프
test_graph = {
'A': [('B', 4), ('C', 1)],
'B': [('A', 4), ('C', 2), ('D', 5)],
'C': [('A', 1), ('B', 2), ('D', 8)],
'D': [('B', 5), ('C', 8)]
}
# 크루스칼 알고리즘 실행
total, edges = kruskal(test_graph)
print(f"최소 비용: {total}")
print("\nMST 간선:")
for u, v, w in edges:
print(f" {u} → {v}: {w}")
이렇게 프림과 크루스칼 알고리즘을 살펴보았다.
두 알고리즘 모두 직관적으로는 단순하다. "가벼운 간선부터 선택한다"는 그리디 전략만 이해하면 된다.
하지만 막상 구현하려고 하면 이야기가 달라진다. 프림은 우선순위 큐를, 크루스칼은 Union-Find를 필요로 한다. 결국 알고리즘의 아이디어는 쉬워도, 이를 효율적으로 구현하는 데는 적절한 자료구조가 뒷받침되어야 한다는 것을 다시 한번 확인할 수 있었다.
출처
쉽게 배우는 알고리즘 | 문병로 - 교보문고
쉽게 배우는 알고리즘 | 귀납적 사고를 통한 문제 해결 기법 훈련이 책은 알고리즘에 대한 지식을 기반으로 제대로 된 프로그래밍을 하는 이들뿐 아니라, 알고리즘 속에 깃든 여러 가지 생각하
product.kyobobook.co.kr
'Computer Science(컴퓨터 과학) > 알고리즘' 카테고리의 다른 글
| 최단 경로(Shortest Path) 알고리즘 (0) | 2025.11.26 |
|---|---|
| 위상 정렬(topological sort) (0) | 2025.11.26 |
| 너비 우선 탐색(Breadth-First Search)과 깊이 우선 탐색(Depth-First Search) (0) | 2025.11.19 |
| 그래프 표현 (0) | 2025.11.18 |
| 그래프(Graph)와 그래프 용어 (0) | 2025.11.18 |








