
너비 우선 탐색(Breadth-First Search)과 깊이 우선 탐색(Depth-First Search)
복잡한 지하철 노선에서 가장 빠른 환승 경로를 찾아본 경험이 있을 것이다.
우리는 노선표를 보면서 가장 적절한 지점을 찾게 된다. 우리가 대체 어떻게 이를 찾았을까? 겉보기에는 단순한 시각적 탐색처럼 느껴지지만, 사실 이 과정에는 일정한 규칙이 숨어 있다.
사실 우리는 알게모르게 너비 우선 탐색(BFS)과 깊이 우선 탐색(DFS)을 하여 찾았을 것이다. 이번 글에서는 이 두 방법에 대해서 이야기해보려고 한다.

1. 넓이 우선 탐색(Breadth-First Search)
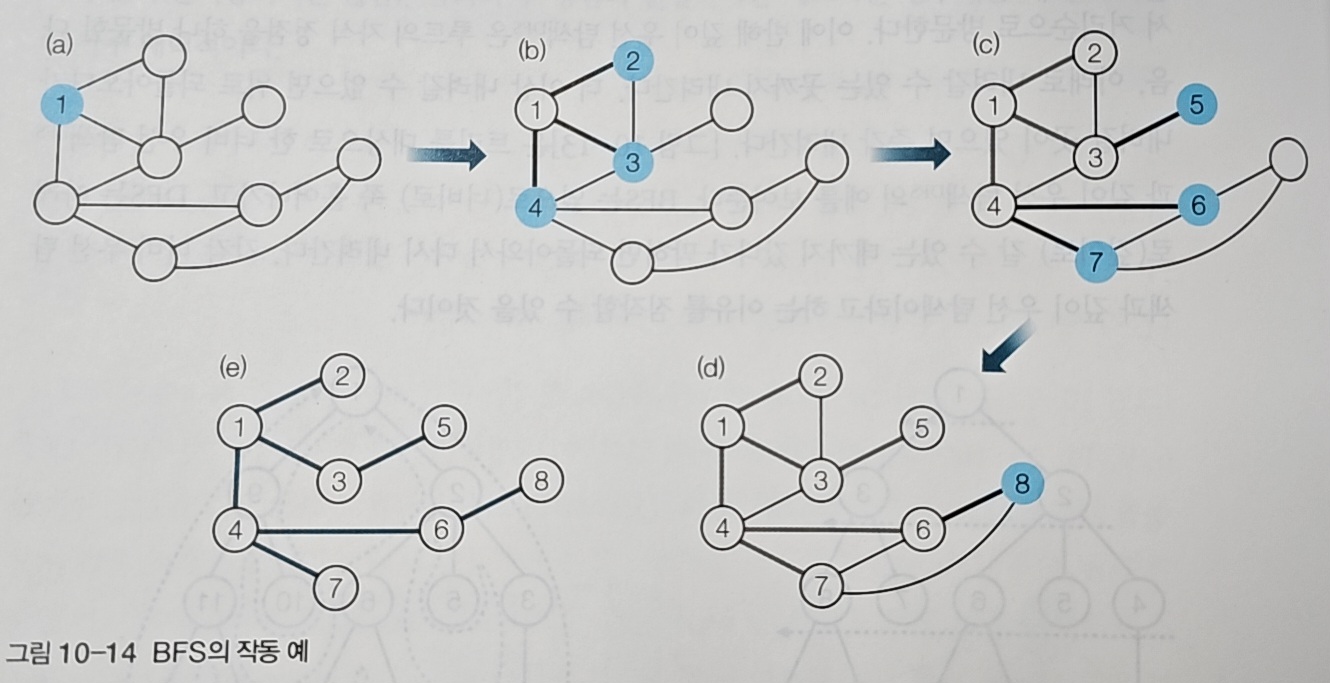
어떤 지점에서 출발해 주변을 먼저 살펴보고 싶은 상황이 있다.
가까운 선택지를 모두 확인한 뒤, 그다음 단계로 넘어가는 방식이다.
지하철에서 “일단 바로 연결된 역들을 먼저 보고, 그다음에 그다음 역들을 보자”라는 사고와 비슷하다
너비 우선 탐색(BFS)은 바로 이런 전략을 구현한 방법이다.
시작 지점의 이웃을 모두 확인하고, 그다음 거리의 이웃을 확인하는 식으로 펼쳐 나간다. 핵심은 “가까운 것부터 차근차근”이다.
이를 자연스럽게 구현하기 위해 큐(Queue)라는 자료구조를 사용한다. 먼저 들어온 것을 먼저 꺼내는 구조라, 탐색의 순서를 보장해 준다. 구현은 다음과 같다.
from collections import deque
# 그래프를 딕셔너리로 표현
graph = {
'A': ['B','C'],
'B': ['D','E'],
'C': ['F'],
'D': [],
'E': ['F'],
'F': []
}
def bfs(start, graph):
# 모든 노드 방문 상태를 False로 초기화
visited = {v: False for v in graph}
# BFS에서 사용할 큐 생성, 시작 노드를 큐에 추가
queue = deque([start])
visited[start] = True # 시작 노드는 이미 방문한 것으로 표시
while queue:
# 큐에서 한 노드를 꺼내어 방문 처리
u = queue.popleft()
print(u, end=' ')
# 꺼낸 노드의 인접 노드를 확인하여 방문하지 않았다면 방문 표시 후 큐에 추가
# 앞선 넣을 때 방문표시해야한다. 꺼낼 때 방문표시하면 중복이 생긴다.
for v in graph[u]:
if not visited[v]:
visited[v] = True
queue.append(v)
print()
bfs('A', graph)이 흐름을 따라가 보면, 왜 BFS가 “가장 가까운 지점부터 넓게 펼쳐 보려는 탐색”인지 자연스럽게 이해된다.
복잡한 구조가 주어졌을 때, 먼저 전체의 윤곽을 빠르게 파악하고 싶은 사람에게 매우 유용한 방식이다.
2. 깊이 우선 탐색(Depth-First Search)
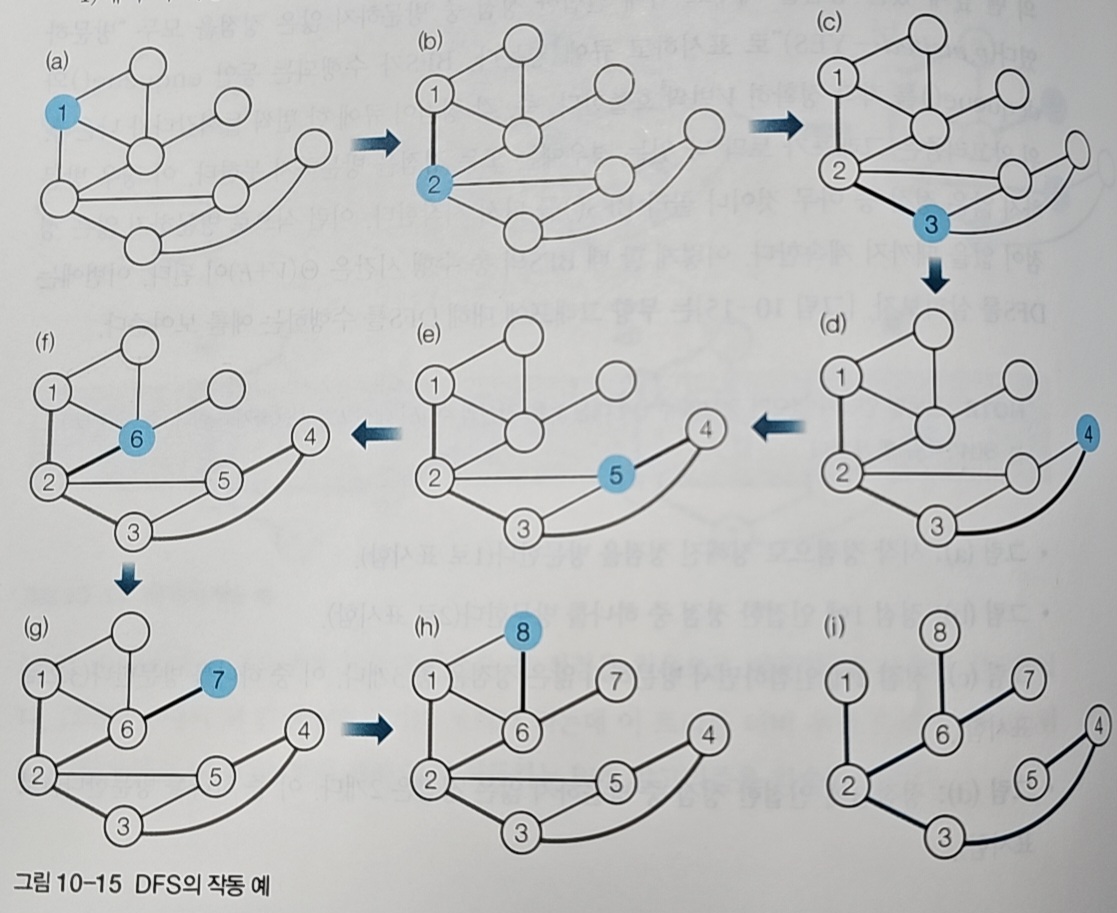
어떤 문제에서는 넓게 살피기보다, 한 길을 끝까지 따라가 본 뒤 다시 돌아와 다른 길을 확인하는 방식이 더 적합하다.
예를 들어 미로를 탐험한다고 할 때, “일단 이 길을 끝까지 가보고, 막히면 돌아와 다른 길로 가자”라는 전략이 있다.
깊이 우선 탐색(DFS)은 바로 이러한 사고를 그대로 알고리즘으로 옮긴 것이다.
하나의 경로를 가능한 끝까지 추적하고, 더 갈 곳이 없을 때 다시 이전 갈림길로 되돌아가 다른 선택지를 탐색한다.
핵심은 “깊게, 그리고 필요하면 되돌아오면서” 살펴보는 방식이다.
이 흐름을 자연스럽게 만드는 것은 스택(Stack) 구조다. 구조다. 가장 최근에 선택한 경로를 우선적으로 계속 탐색하는 데 알맞기 때문이다. 이의 구현은 다음과 같다.
# 그래프를 딕셔너리로 표현
graph = {
'A': ['B','C'],
'B': ['D','E'],
'C': ['F'],
'D': [],
'E': ['F'],
'F': []
}
def dfs(start, graph):
# 모든 노드 방문 상태를 False로 초기화
visited = {v: False for v in graph}
# DFS에서 사용할 스택 생성, 시작 노드를 스택에 추가
# 스텍은 리스트에서 구현할 수 있다.
stack = [start]
while stack:
node = stack.pop()
# 만약에 방문처리를 꺼내고 나서 하고 싶다면 그냥 visited[node] = True를 적어서는 안된다.
# 이전에 꼭 if not visited[node]: 이러한 조건문을 적어놔야 중복처리가 되지 않는다.
if not visited[node]:
visited[node] = True
print(node, end=' ')
# 현재 노드의 인접 노드를 스택에 추가
# 스택 특성상 역순으로 넣어야 방문 순서가 직관적
for neighbor in reversed(graph[node]):
if not visited[neighbor]:
stack.append(neighbor)
print()
dfs('A', graph)DFS의 흐름을 따라가 보면, 왜 이것이 “한 경로를 끝까지 조사하는 데 적합한 탐색”인지 쉽게 체감된다.
전체 구조를 세밀하게 확인하거나, 특정 경로의 성질을 분석해야 할 때 특히 유용한 방식이다.
특히 이 두 알고리즘은 코딩테스트는 물론, 의외로 실무에서도 자주 활용된다. 지금 예로 든 지하철 환승 경로 찾기 역시 이러한 방법으로 해결할 수 있다.
출처
쉽게 배우는 알고리즘 | 문병로 - 교보문고
쉽게 배우는 알고리즘 | 귀납적 사고를 통한 문제 해결 기법 훈련이 책은 알고리즘에 대한 지식을 기반으로 제대로 된 프로그래밍을 하는 이들뿐 아니라, 알고리즘 속에 깃든 여러 가지 생각하
product.kyobobook.co.kr
'Computer Science(컴퓨터 과학) > 알고리즘' 카테고리의 다른 글
| 위상 정렬(topological sort) (0) | 2025.11.26 |
|---|---|
| 최소 신장 트리와 프림(Prime), 크루스칼(Kuskal) 알고리즘 (0) | 2025.11.23 |
| 그래프 표현 (0) | 2025.11.18 |
| 그래프(Graph)와 그래프 용어 (0) | 2025.11.18 |
| 이분 탐색 (Binary Search) 기법 (0) | 2025.11.10 |








